Reveal SAP EWM – Warehouse Order sorting in Queues
Reveal SAP EWM
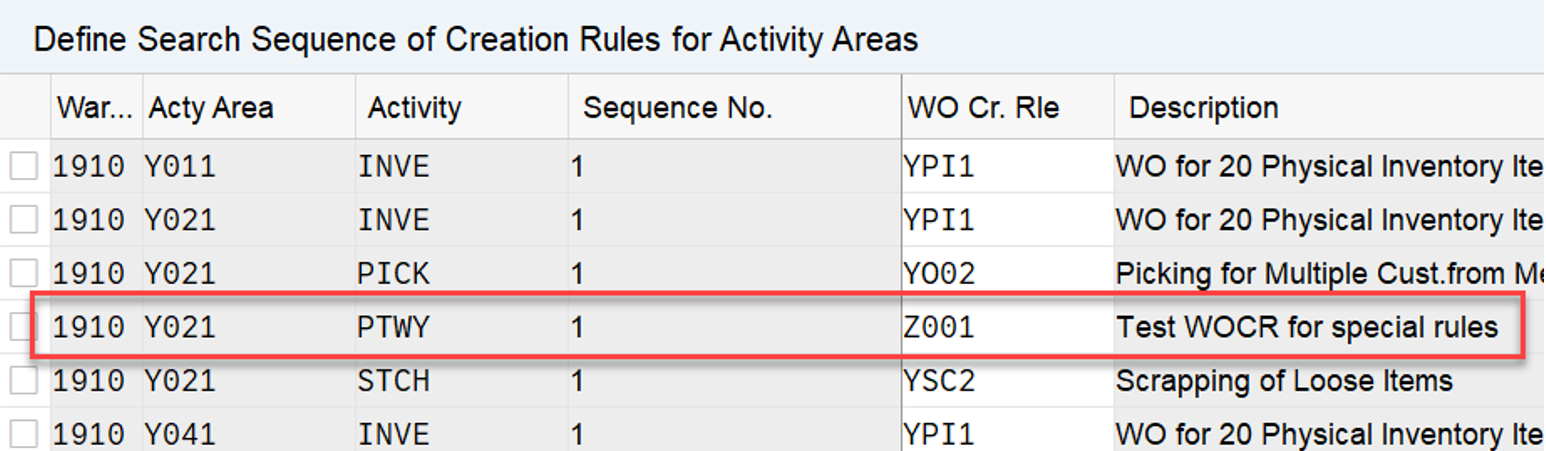
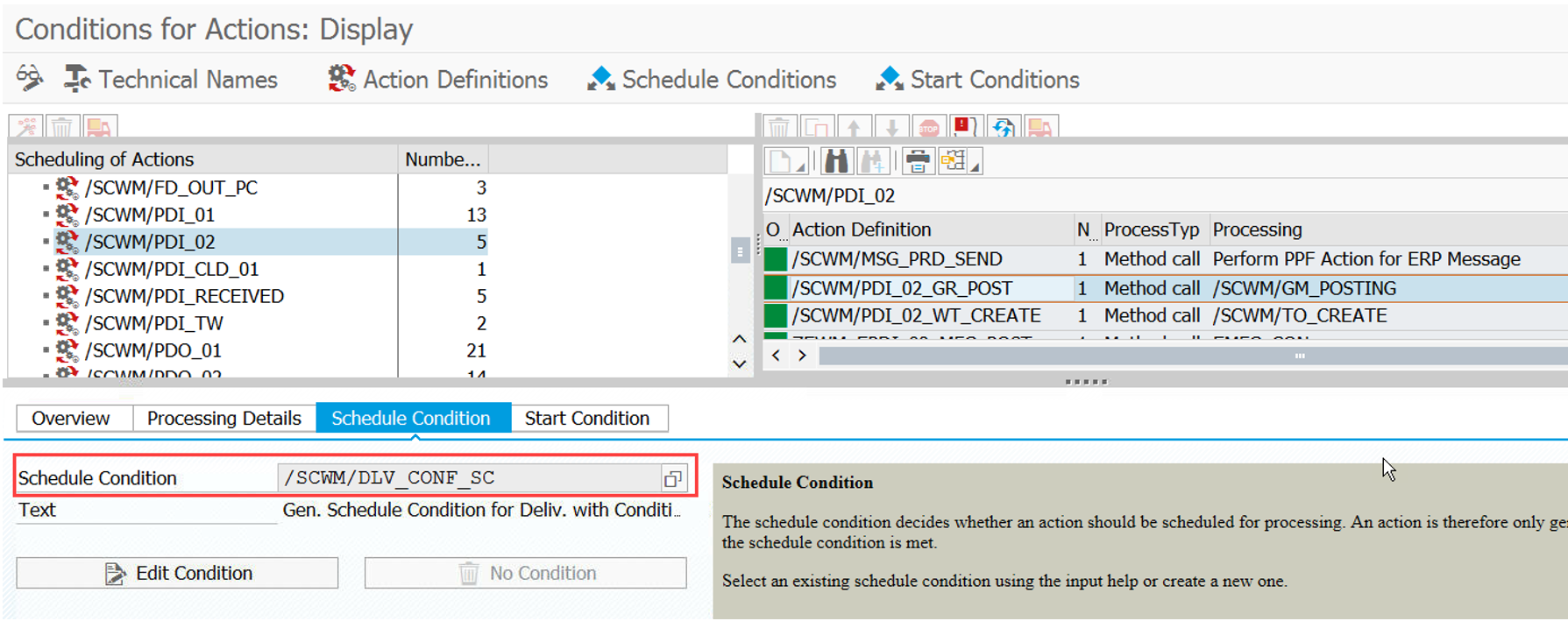
Sorting of Warehouse orders within Queues
My new blog post is offers a comprehensive summary of warehouse order sorting in queues. I delve deep behind the scenes and reveal a few secrets along the way.
The article begins with the basics, explains sorting with and without pre-assignment of warehouse orders to resources, and concludes with an analysis of the logic in the context of physical inventory and task interleaving.
Context
It is important to understand that we are only talking about the sorting within one queue. With a system-guided selection or with a task interleaving approach the resource group of the current resource might be assigned to multiple queues and the queue sequence as such is evaluated before the sorting within one queue becomes relevant. With this article however, we are looking at one single queue only and the sorting within this queue.
Also certain warehouse orders in the queues might not be considered for the resource type of the resource which the current user used to login (e.g. resource execution constraints). This filtering of warehouse orders is also not in scope for this article as it has no impact on the actual sorting of applicable WOs. To say it again – Pure sorting, nothing else!
Agenda for this blog-post
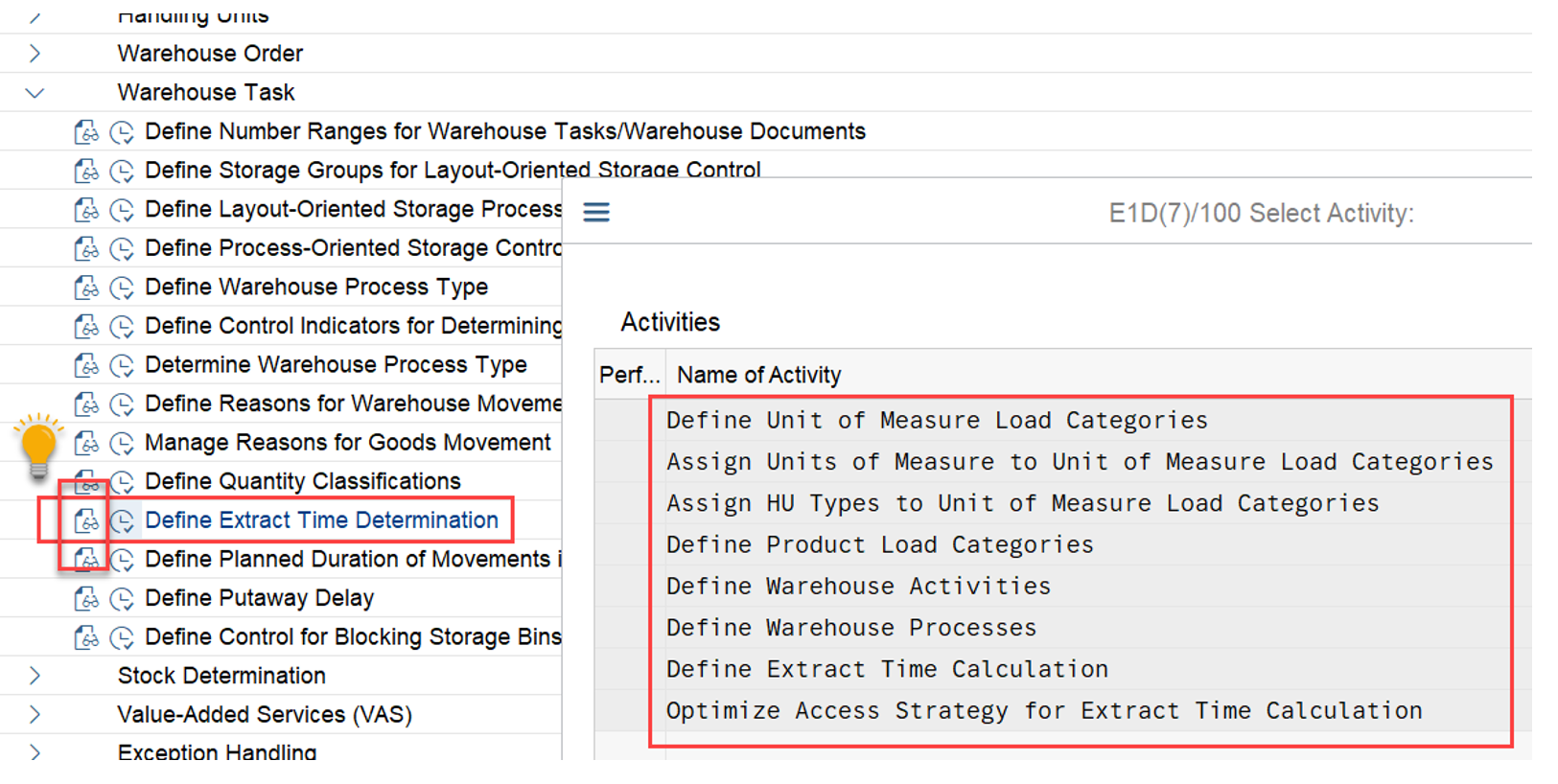
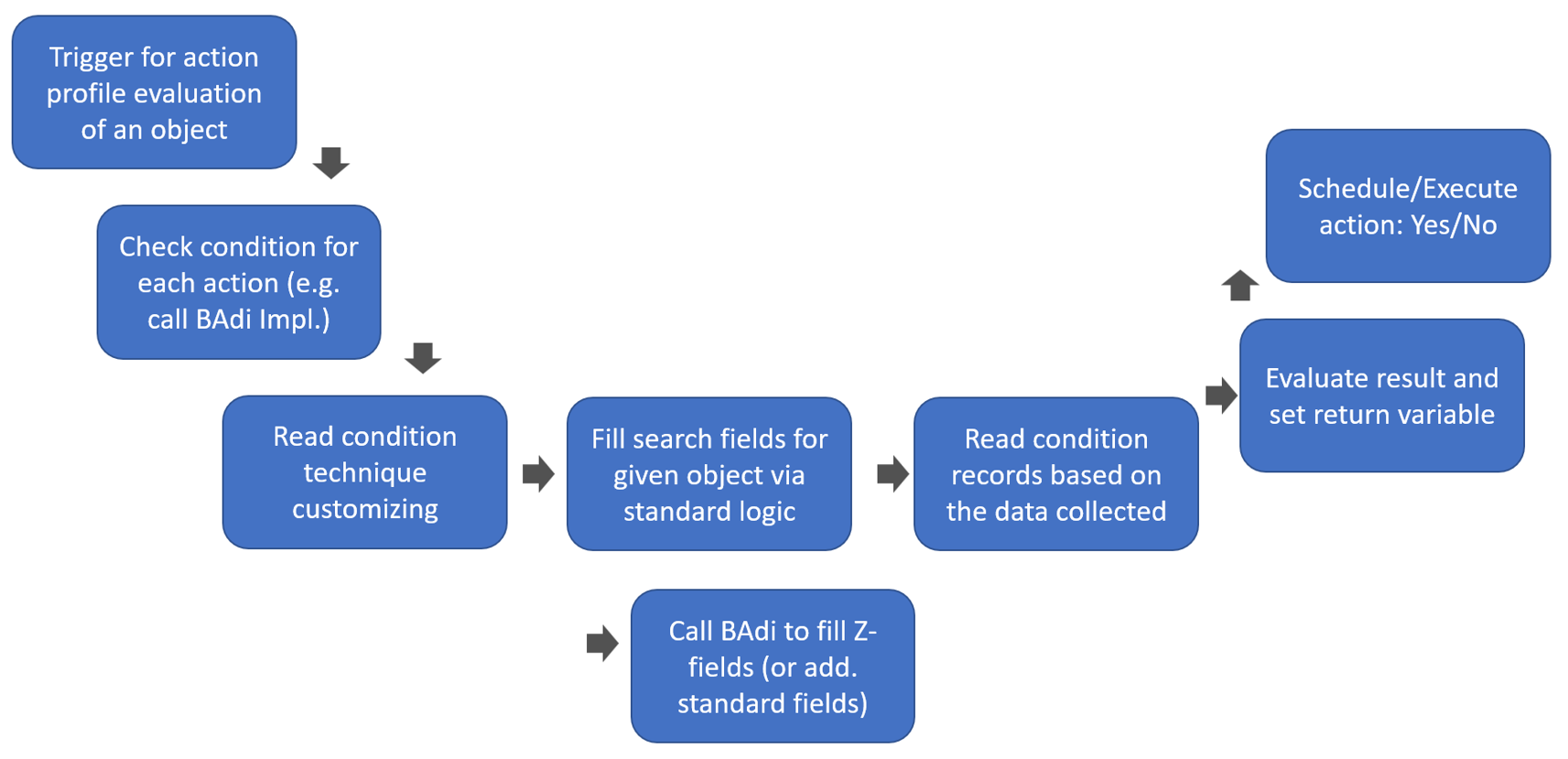
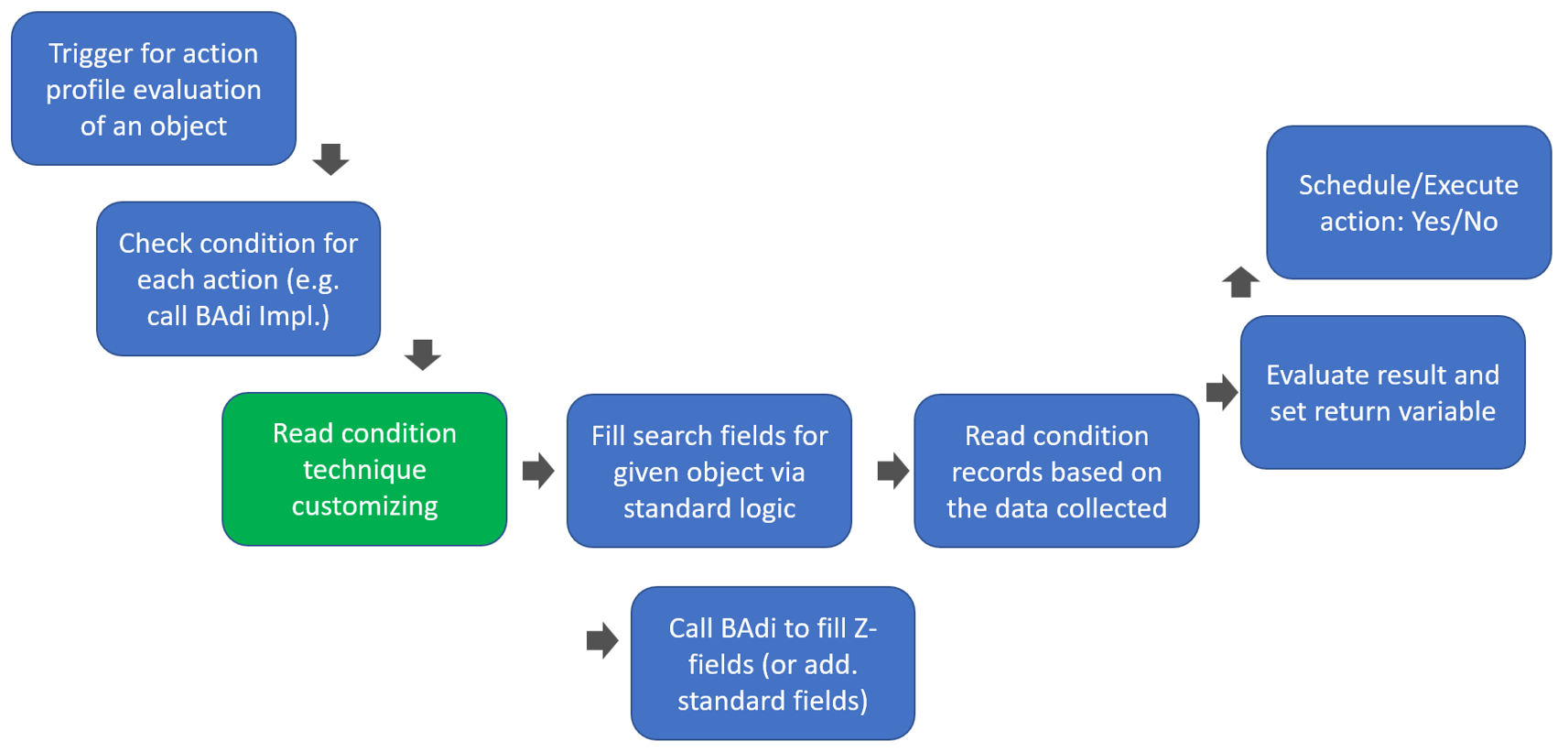
- Main part: How are WOs technically being sorted in a queue?
- How does the EWM standard sort the WOs within the queues? Which factors have an impact? How are those factors being calculated?
- How does this sorting logic change in case multiple WOs are pre-assigned to the current resource?
- What options does EWM offer to implement a custom logic for the sorting?
- Party-knowledge
- Sorting of WOs for physical inventory
- Sorting while interleaving being active
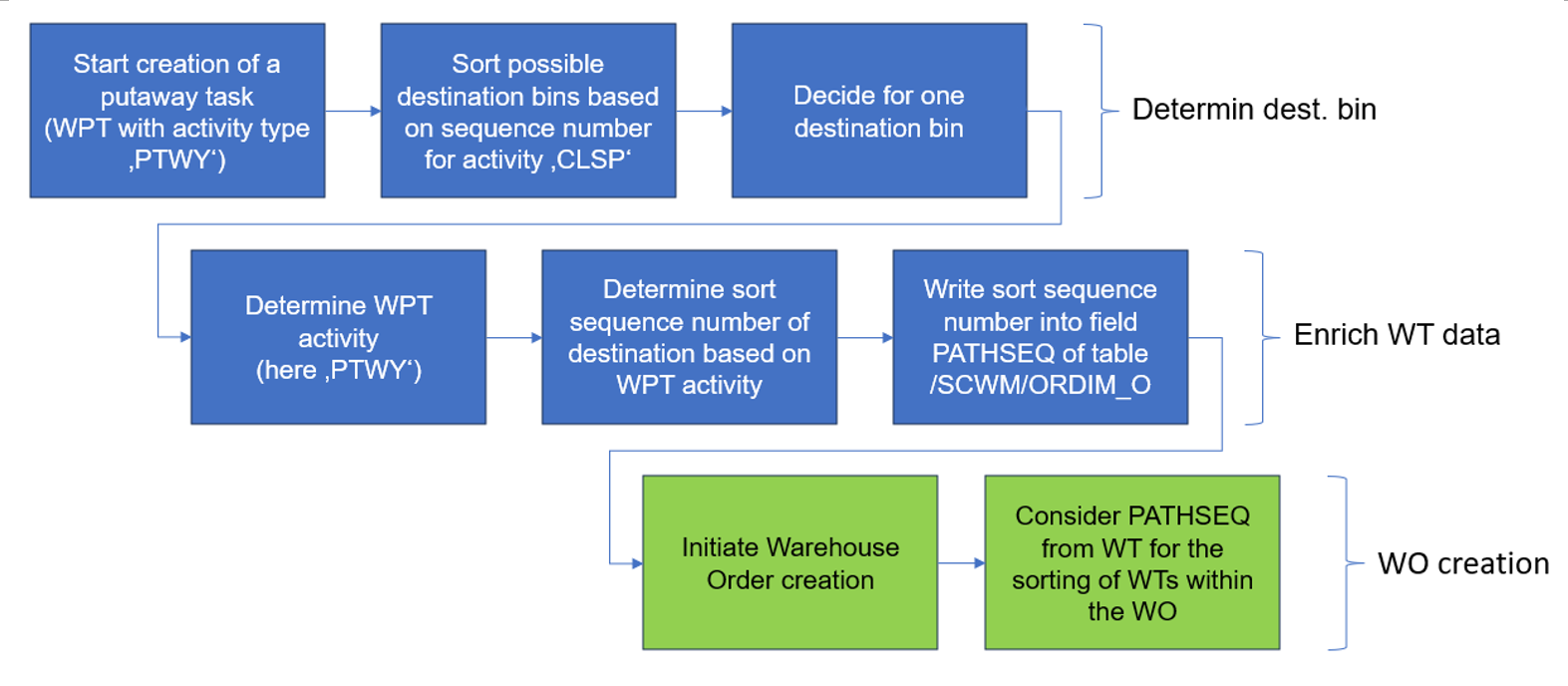
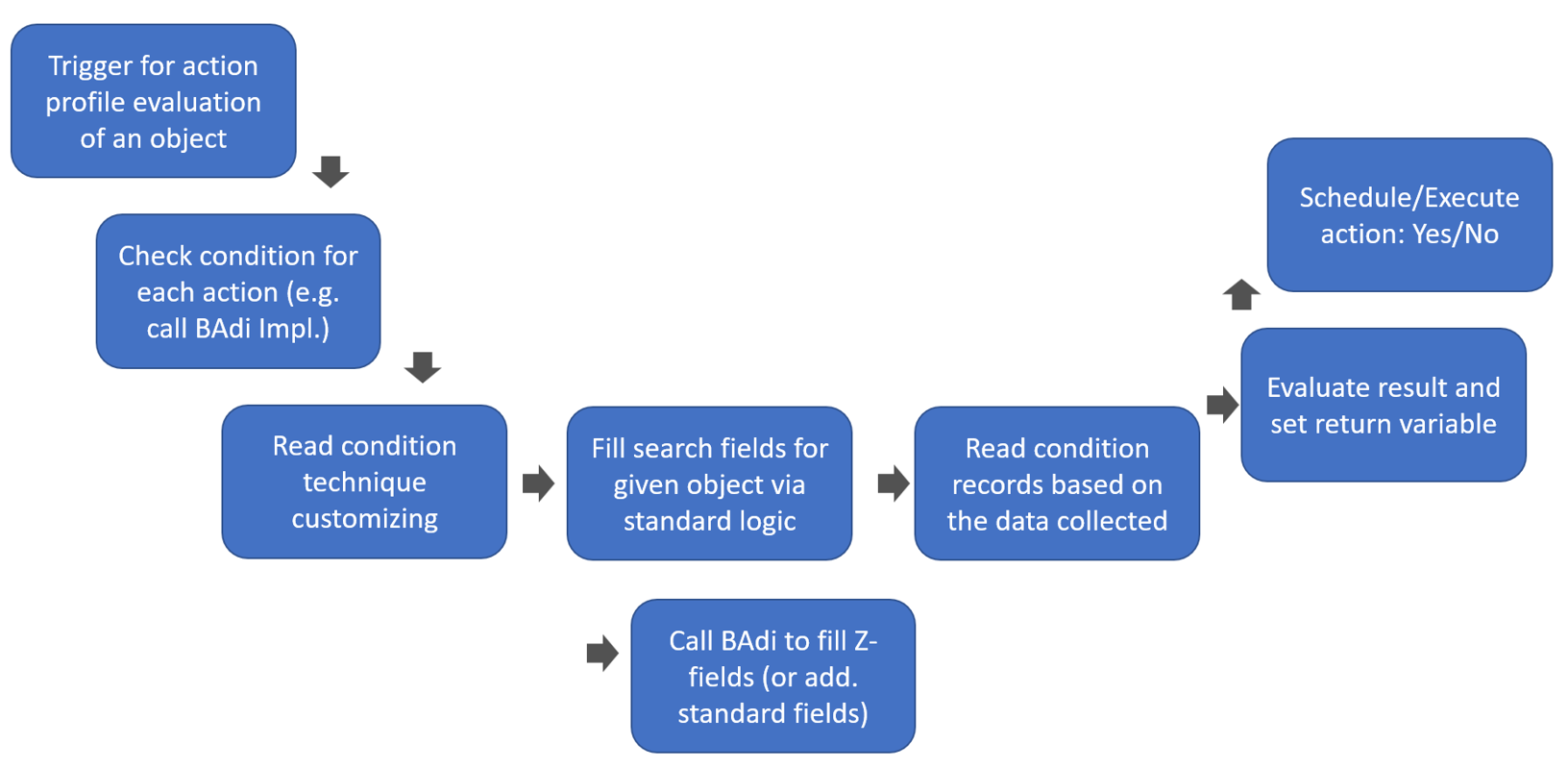
How does the sorting work?
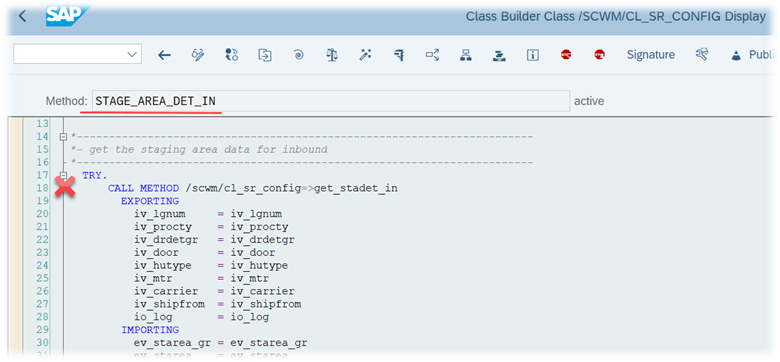
Let us start again from the SAP help text
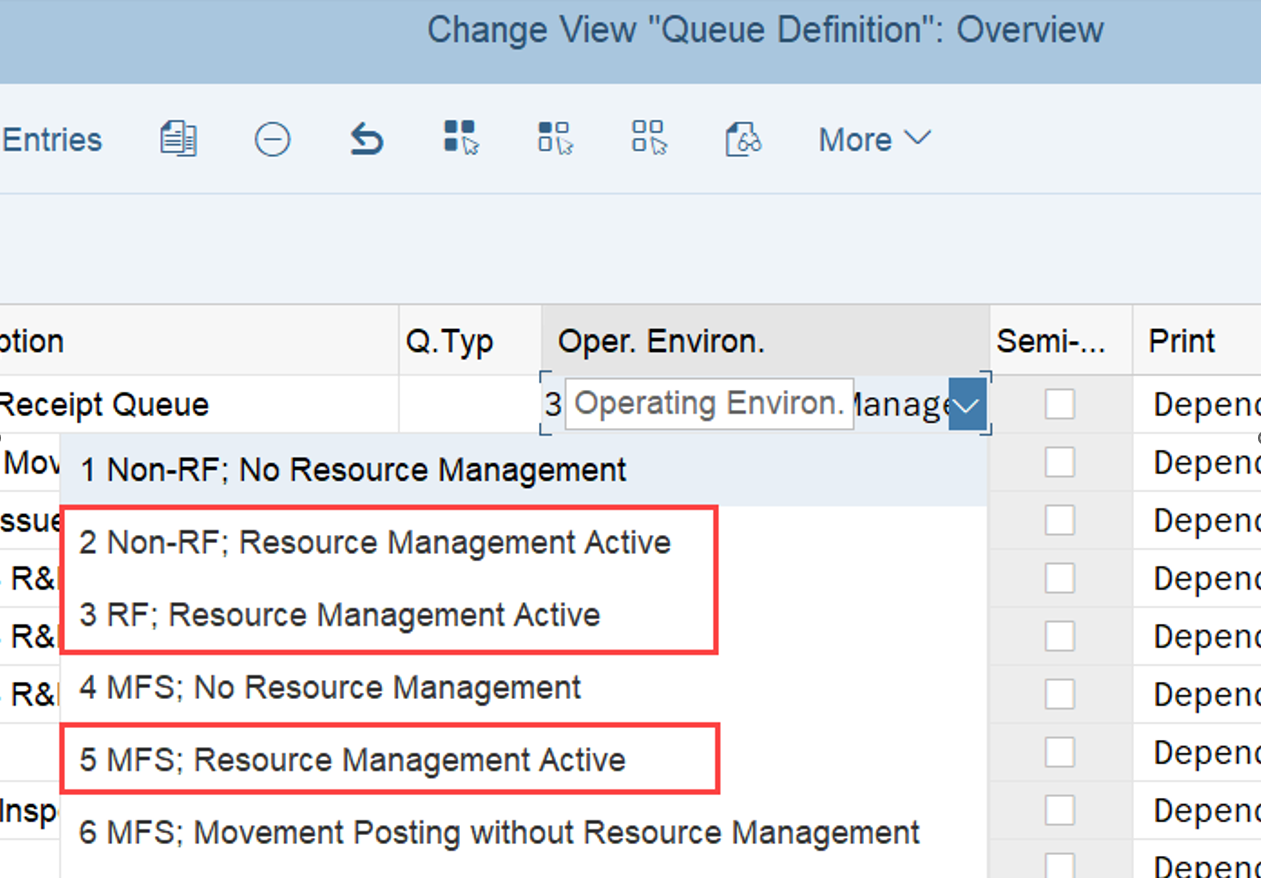
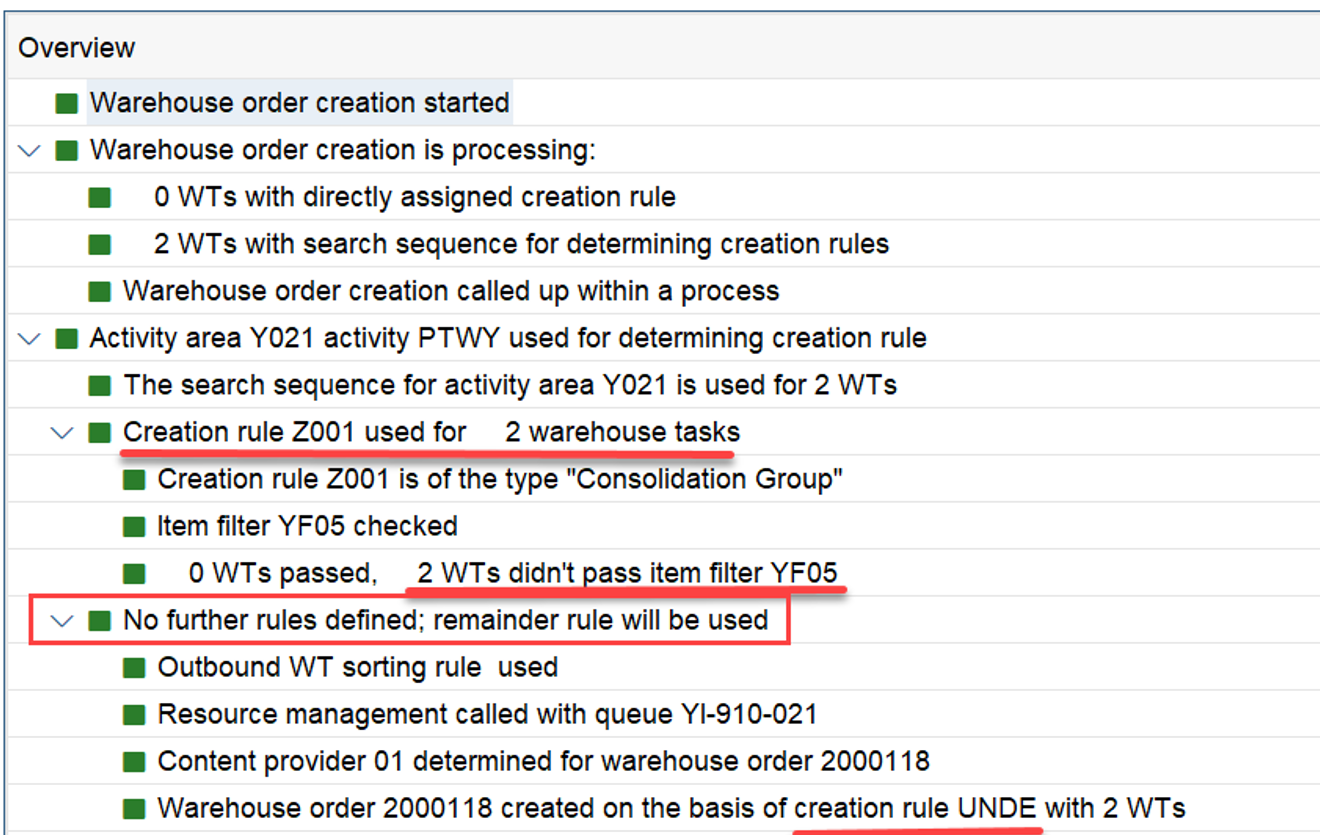
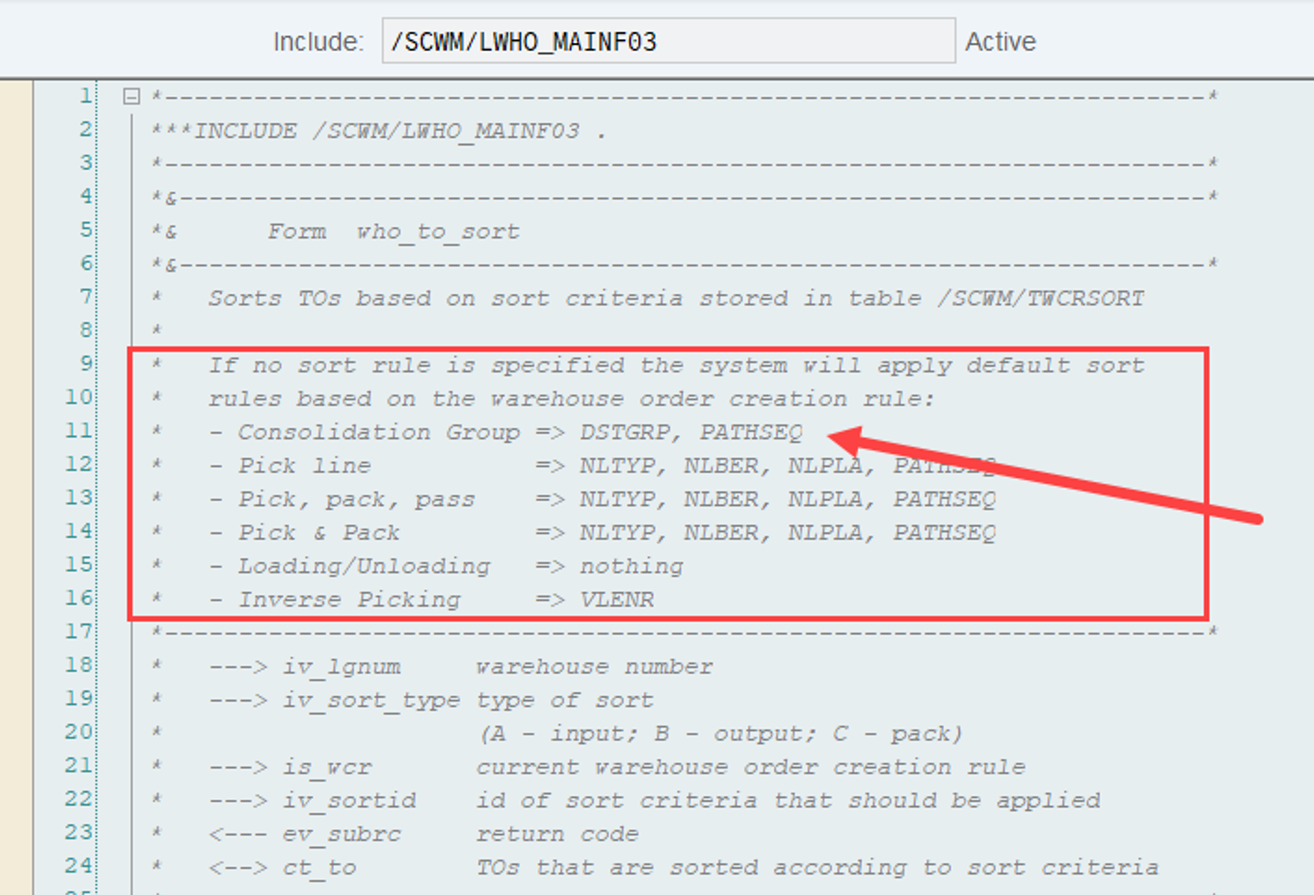
If more than one WO falls within any of these queue classifications, the WOs are sorted as follows:
In ascending order, by latest starting date (LSD)
In descending order, by execution priority.
So we learned that the sorting depends on two values:
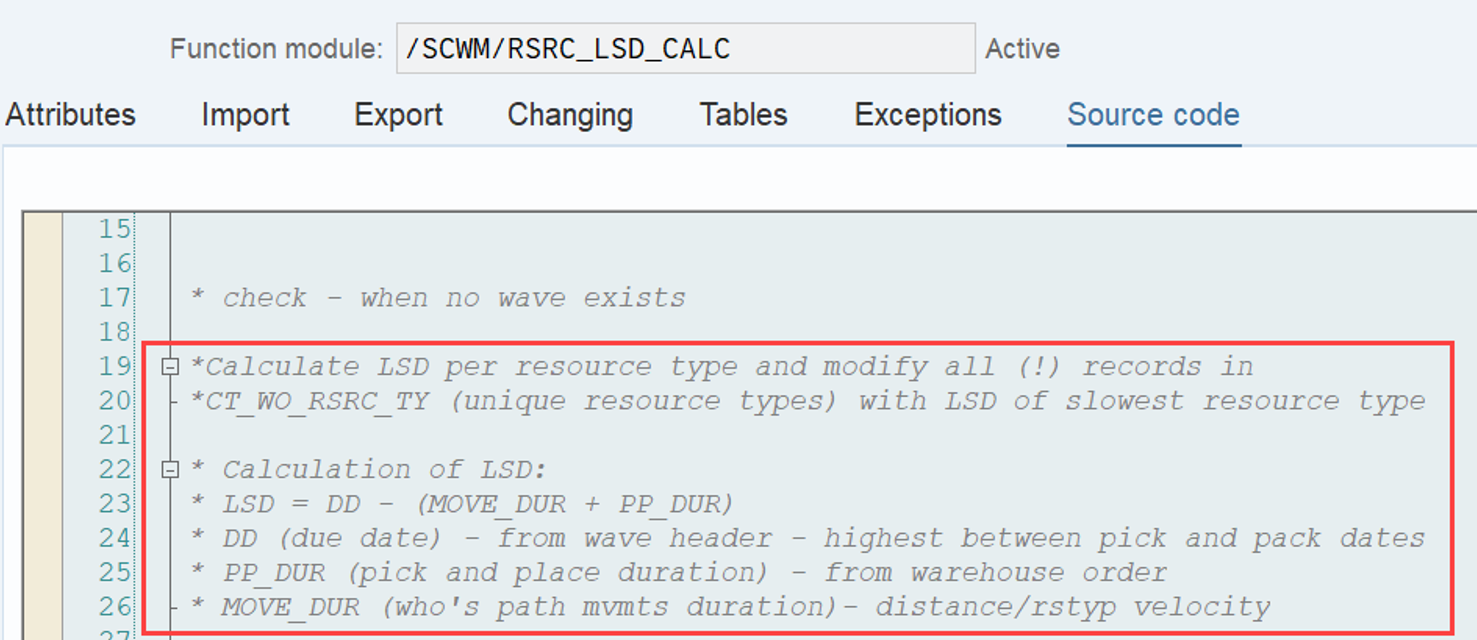
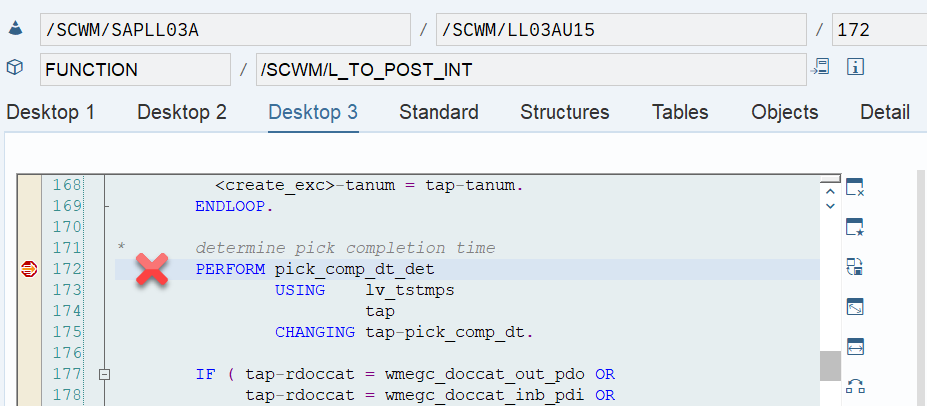
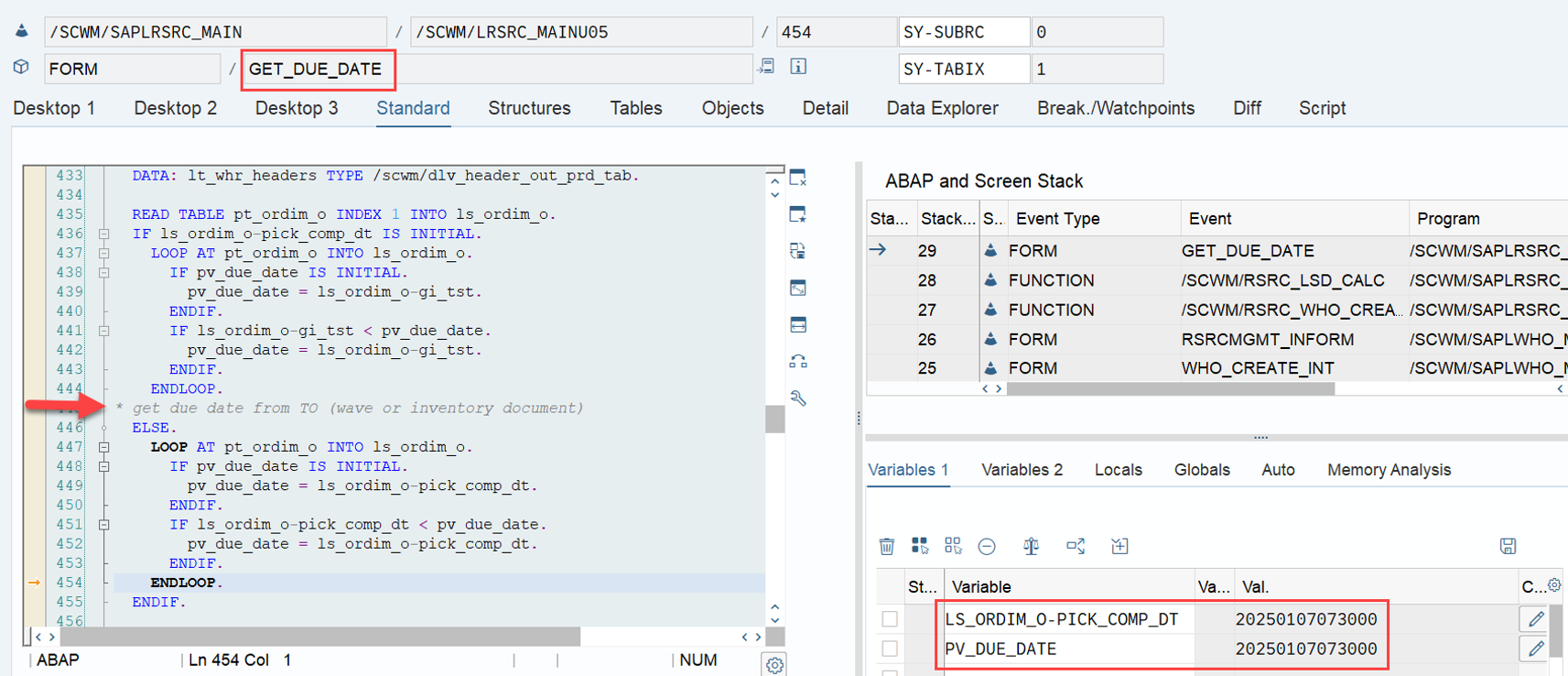
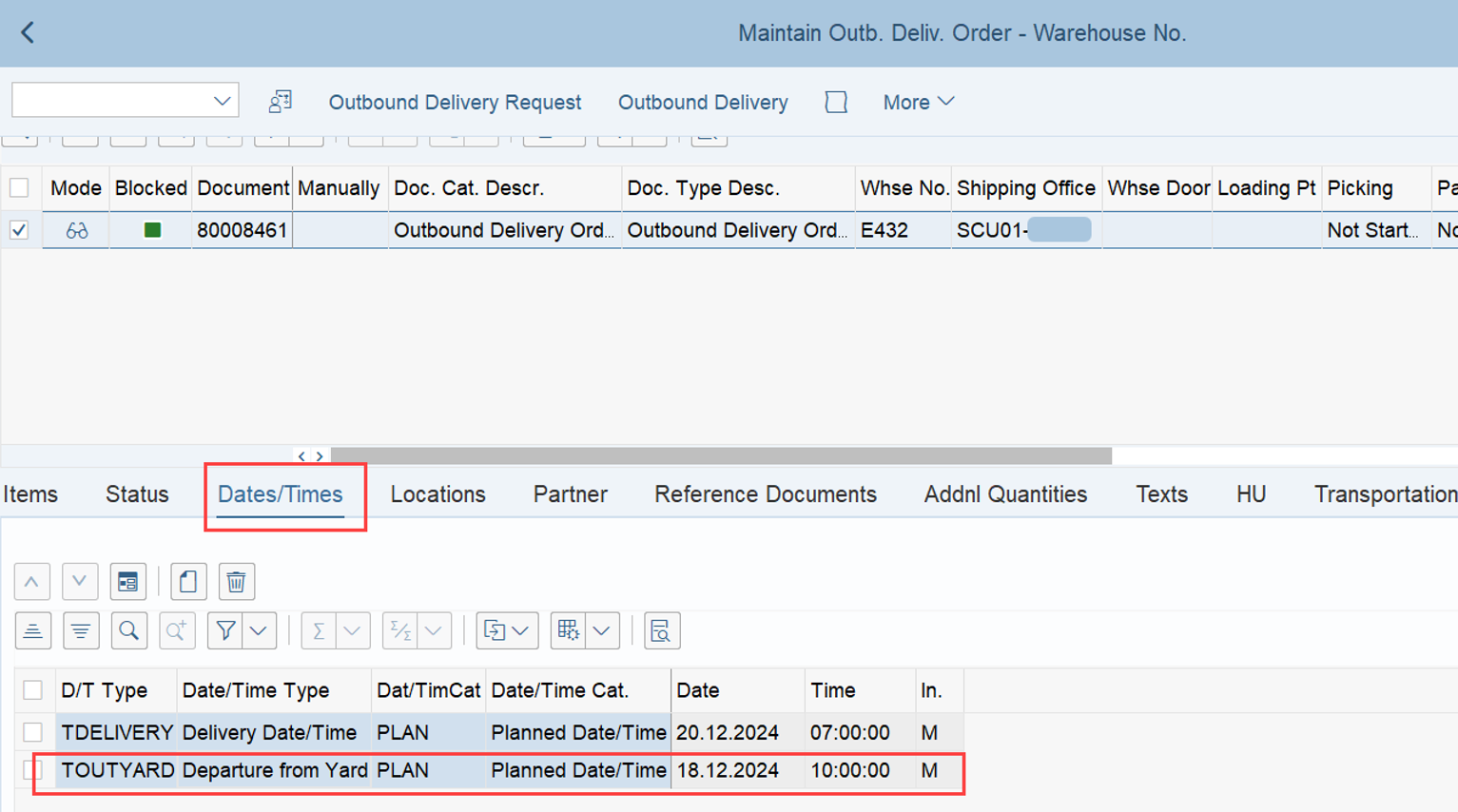
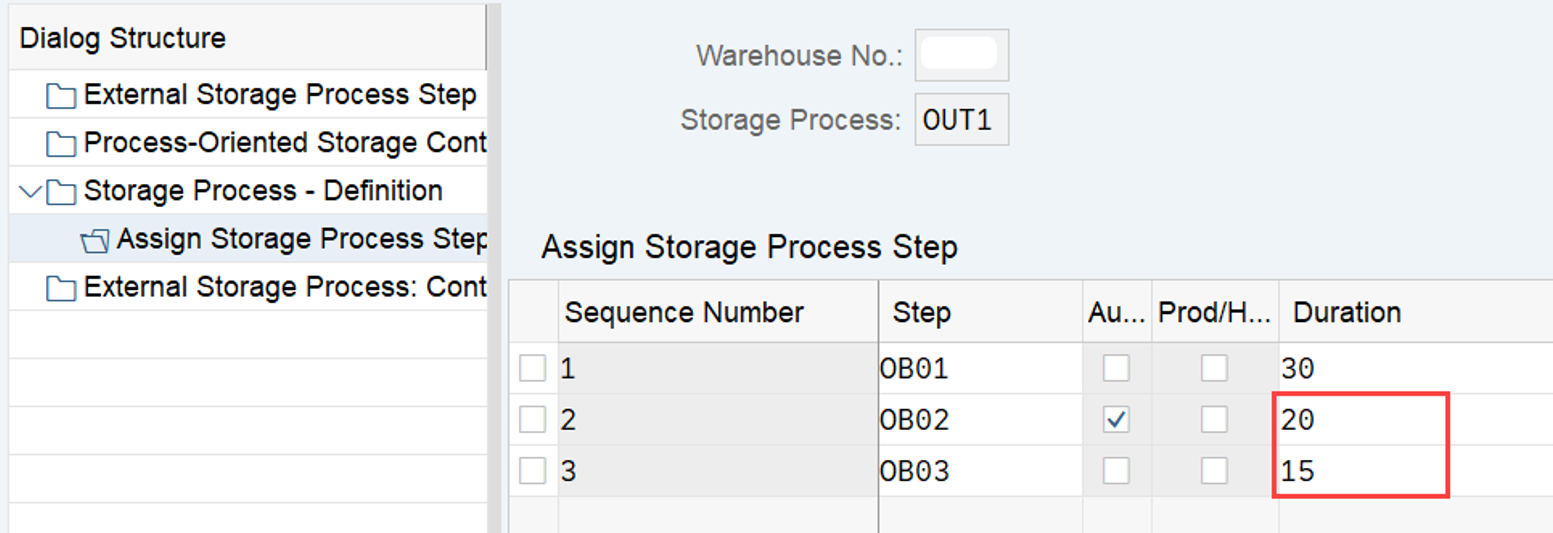
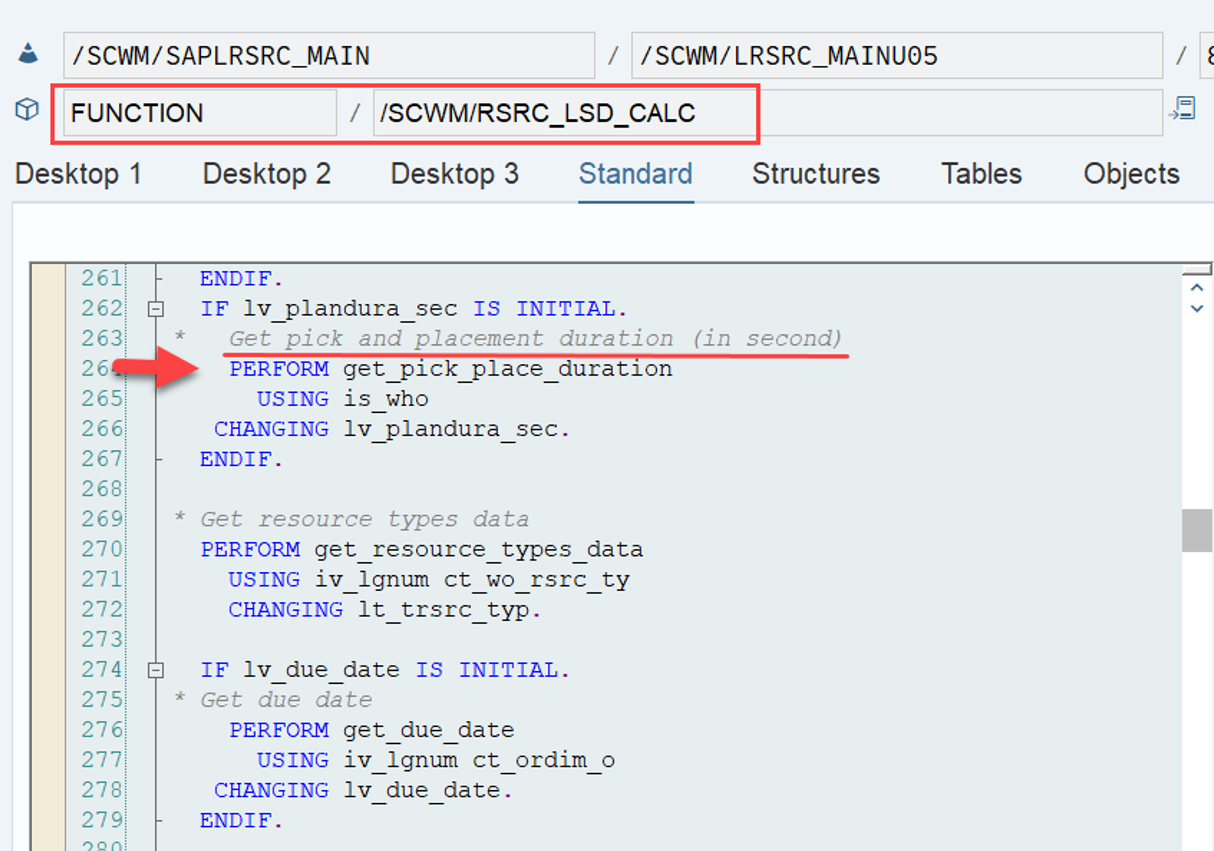
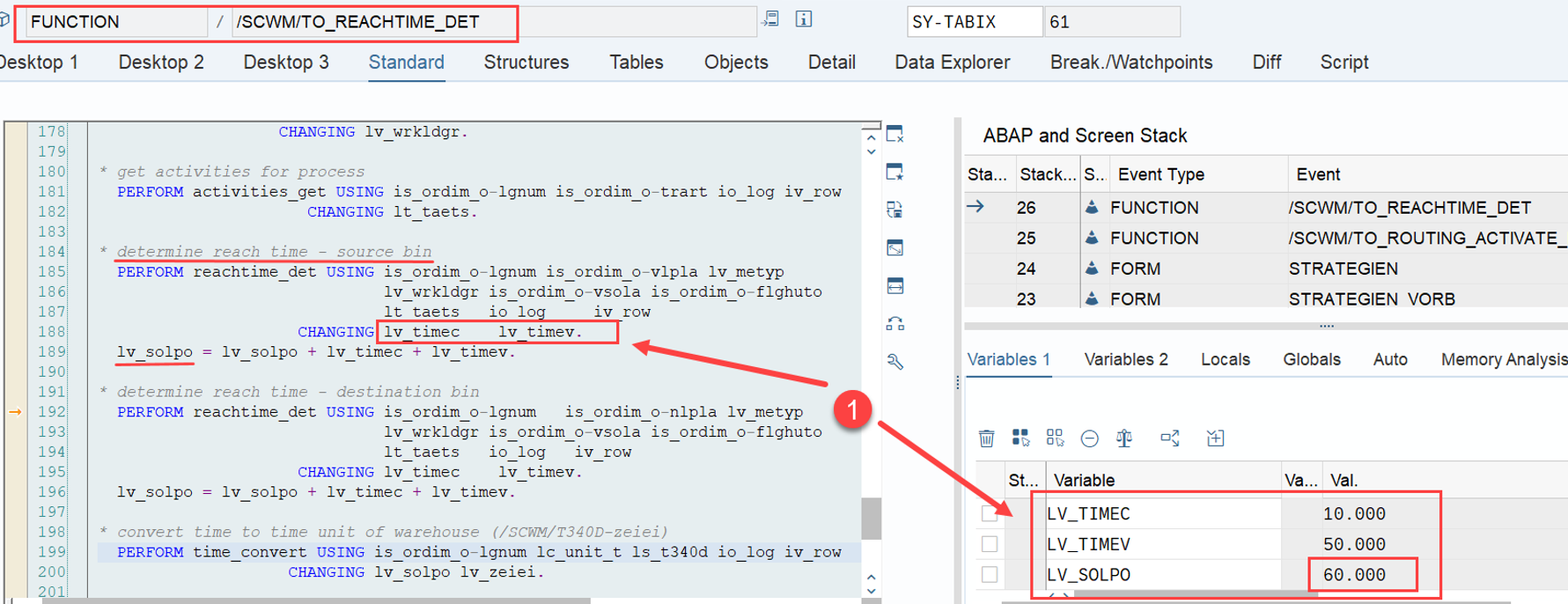
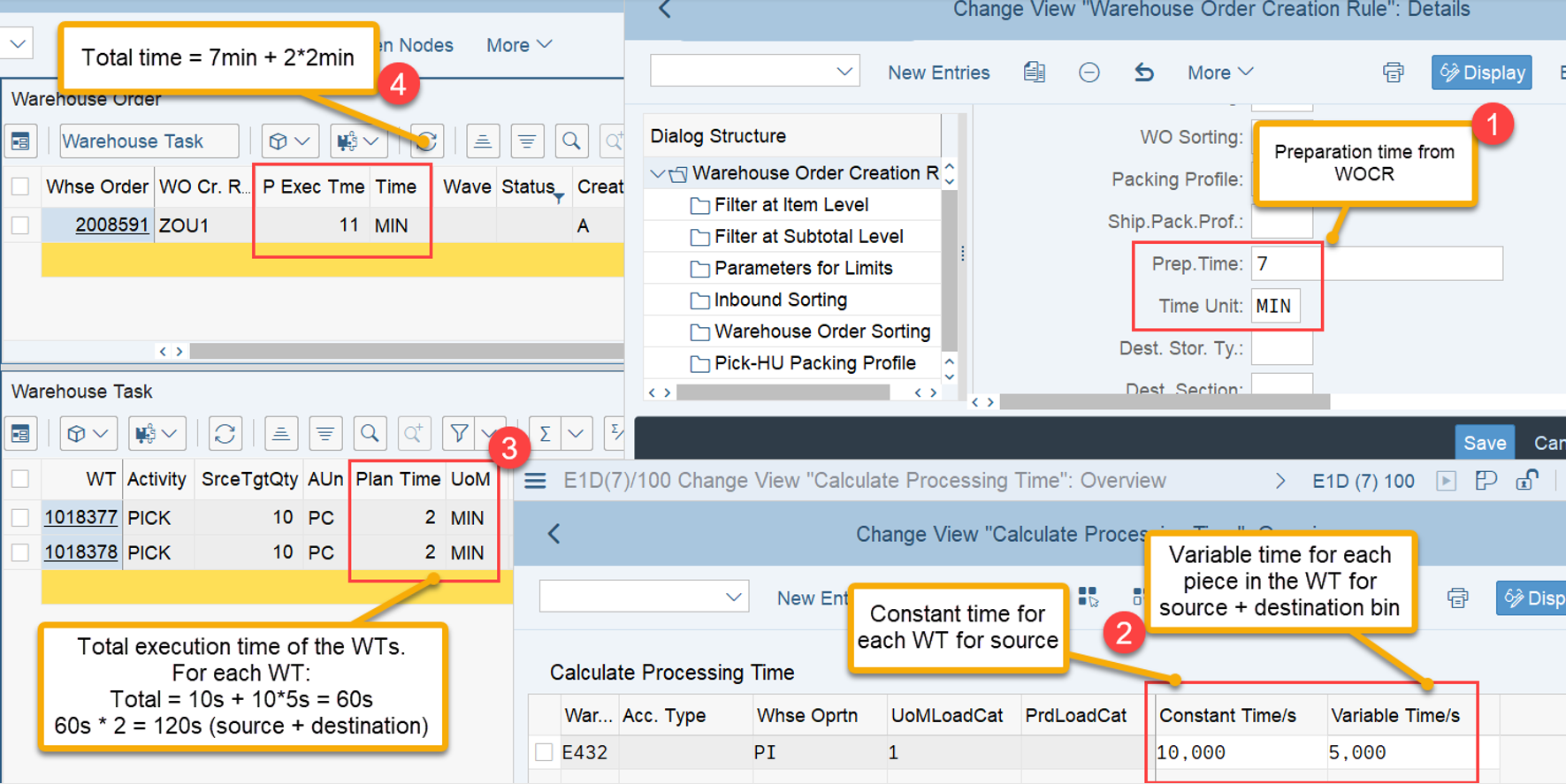
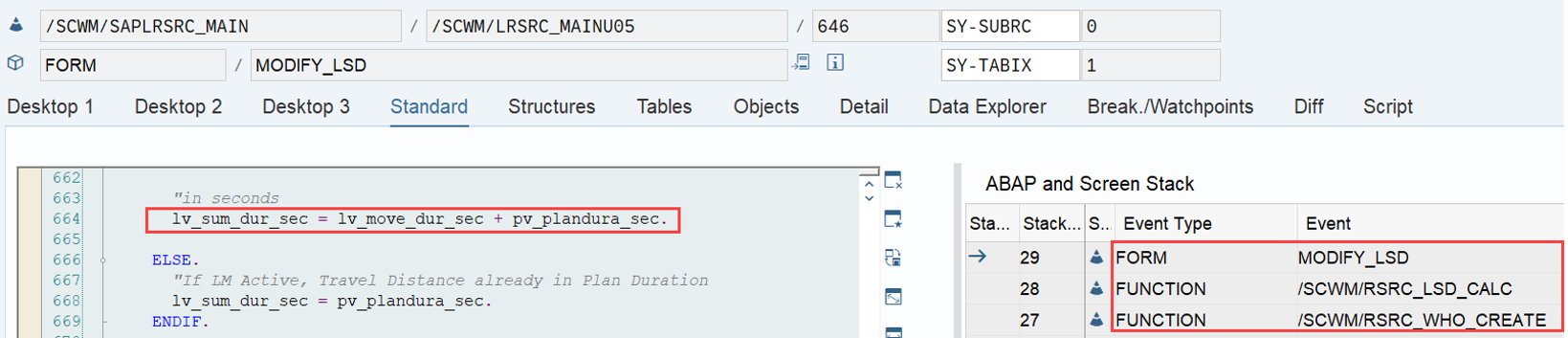
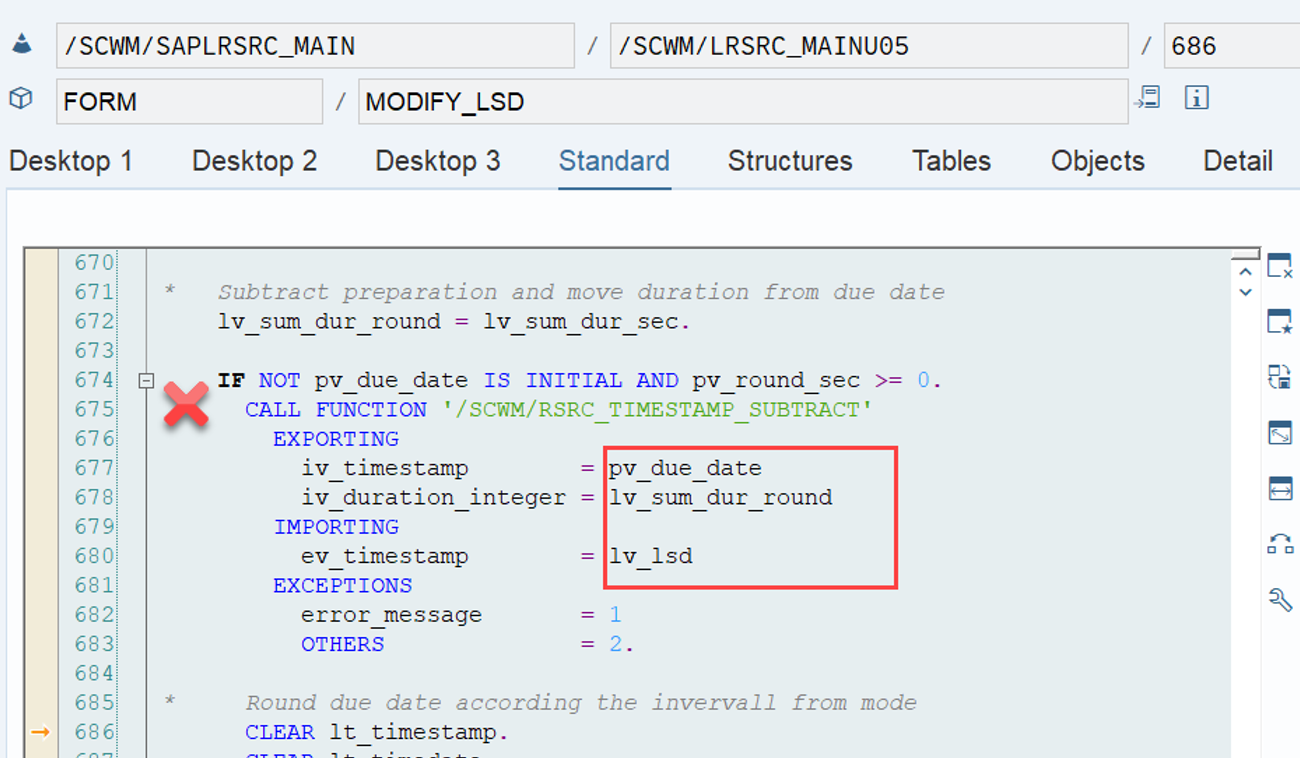
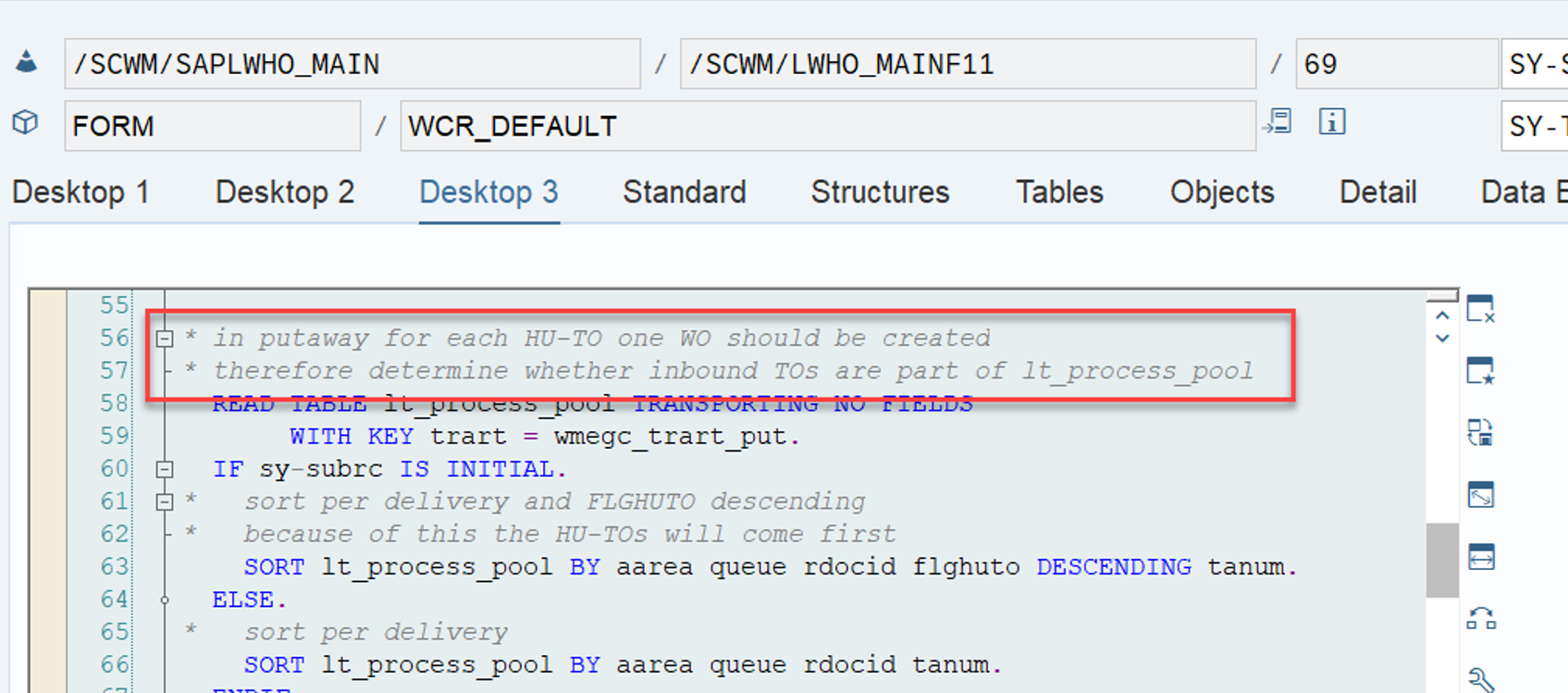
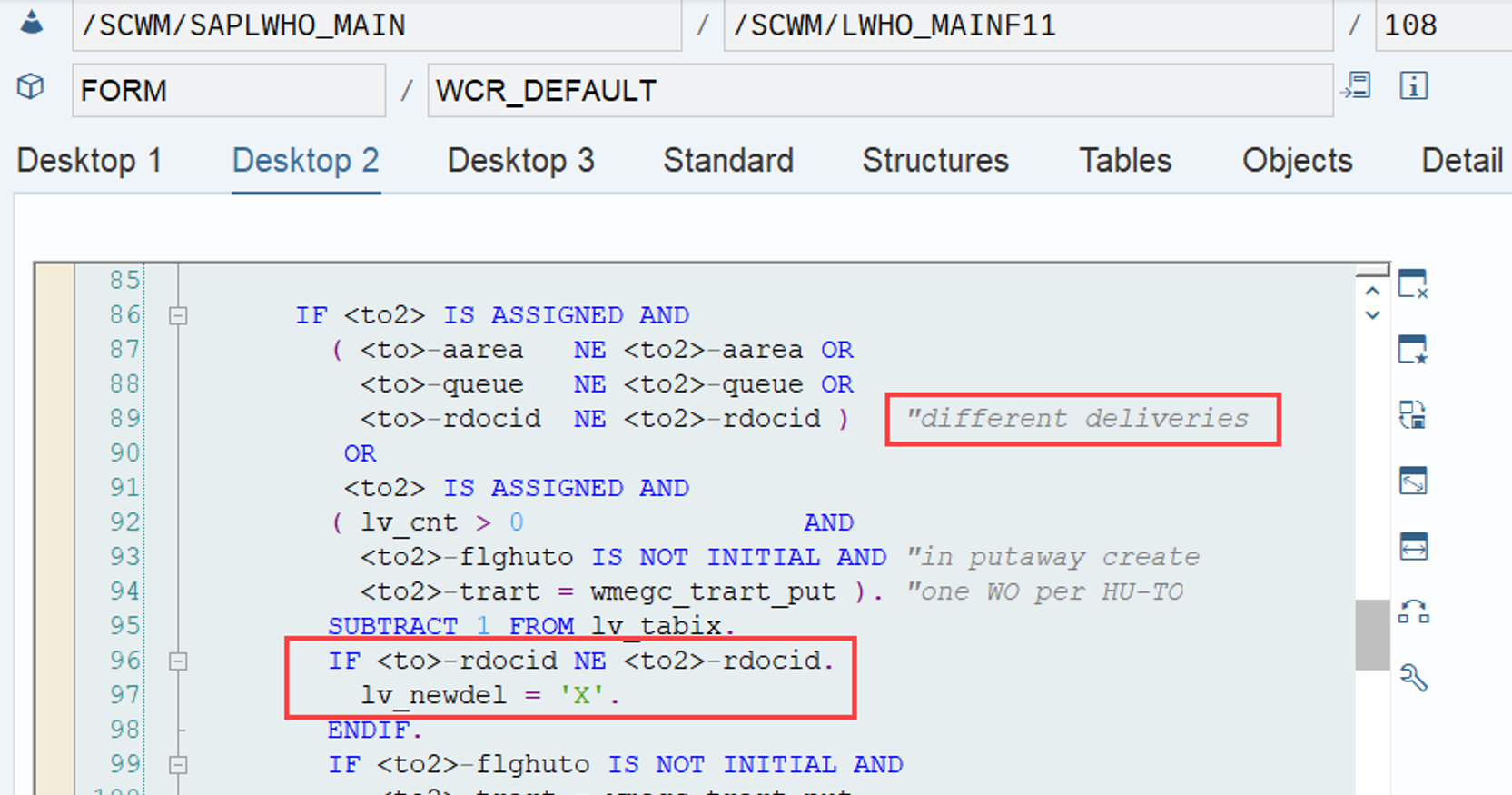
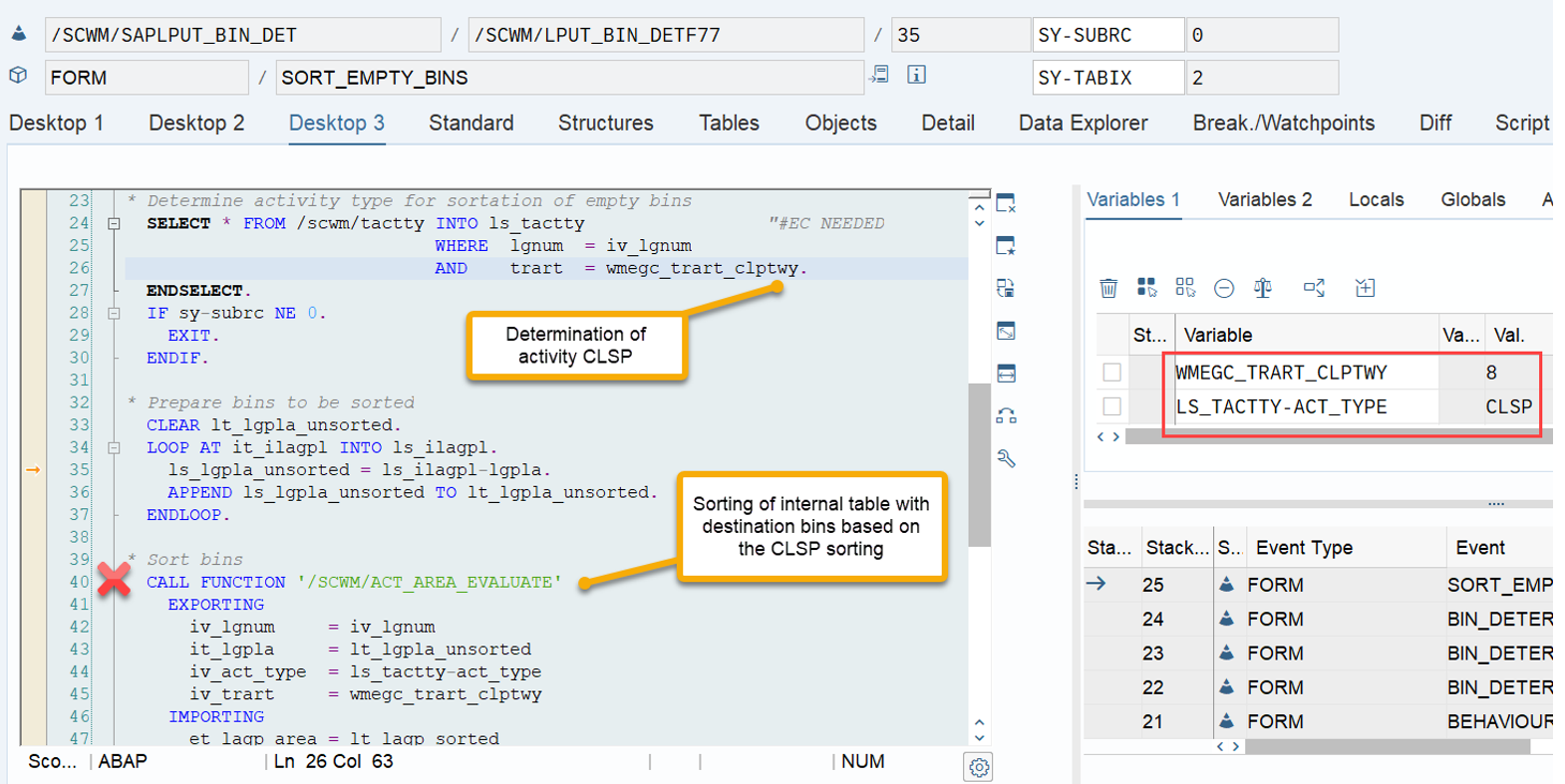
LSD calculation: This is explained in my other video or blog-post: It is calculated based on the following formula: LSD = WO due date – (planned execution duration + planned movements duration)
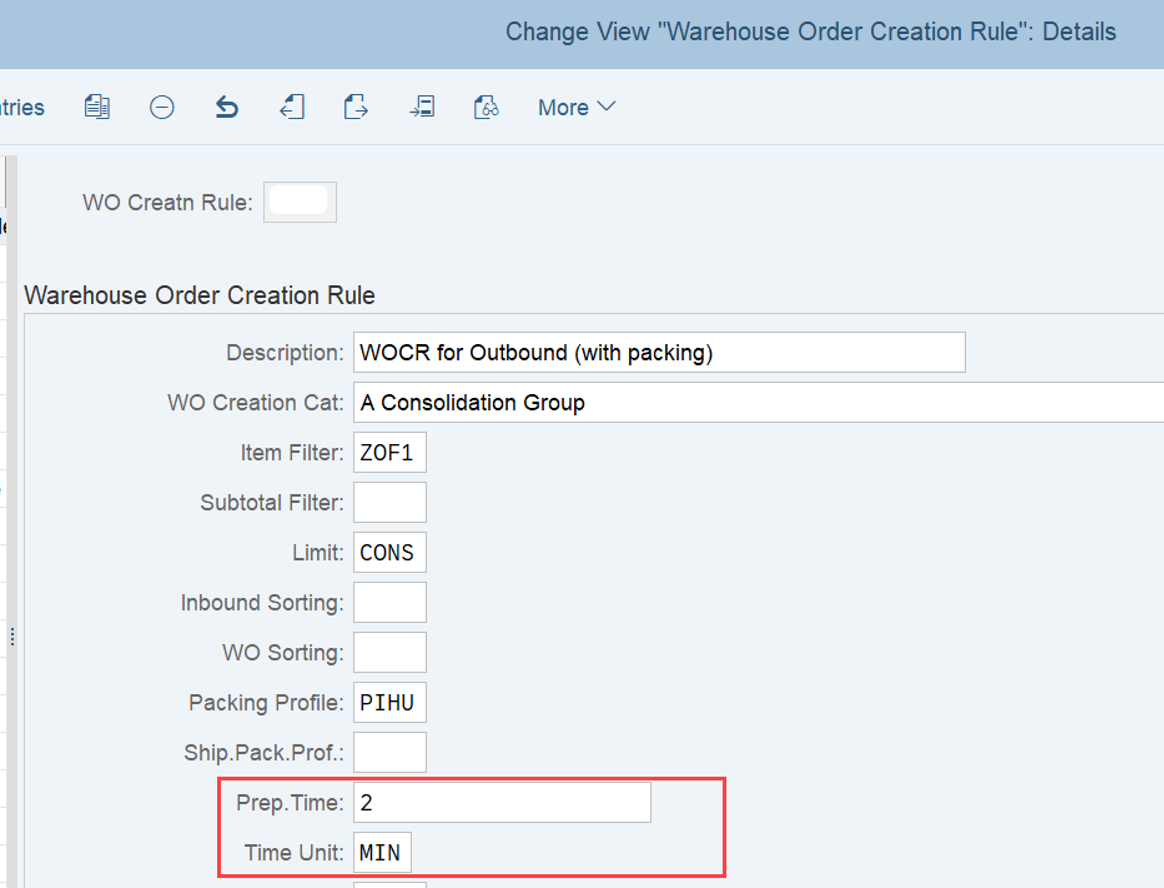
WO Prioritization: This has a good SAP help text with lots of examples for the calculation. For each WT in the WO the priority is calculated with the following formula: Priority = (BAT Weighting/100 x BAT Priority Value) + (HUTG Weighting/100 x HUTG Priority Value) + (WPC Weighting/100 x WPC Priority Value). The WO priority is then set to the priority of its WT with the highest priority value.
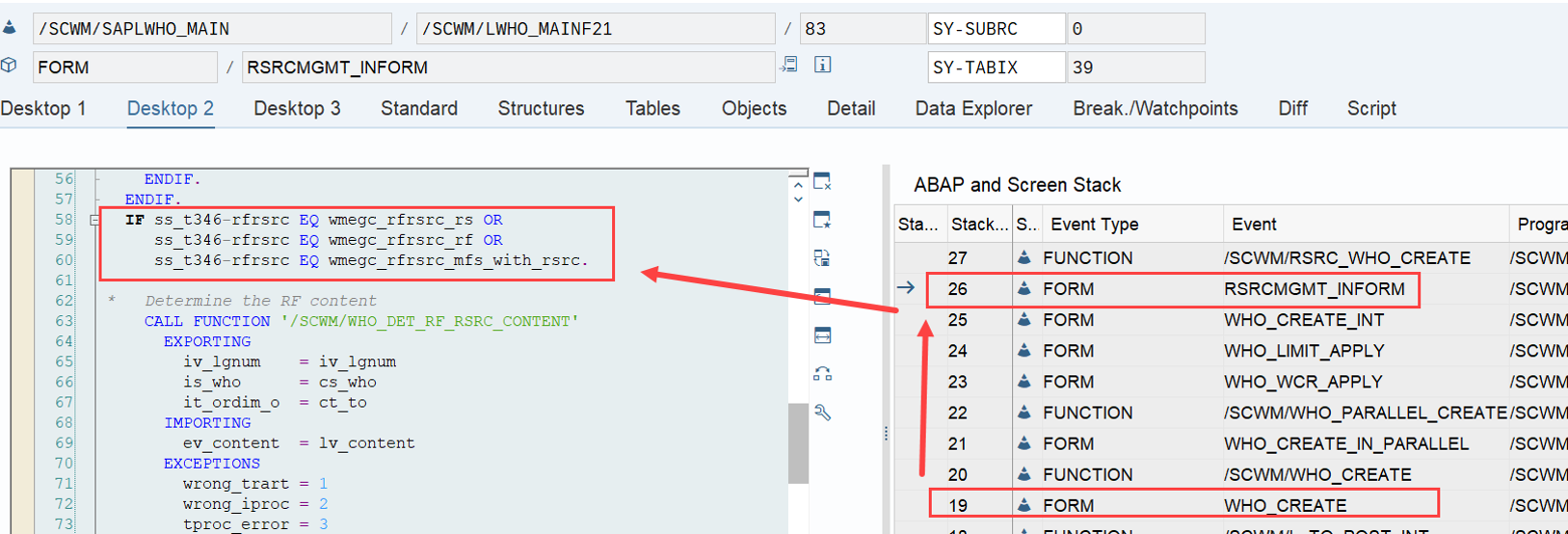
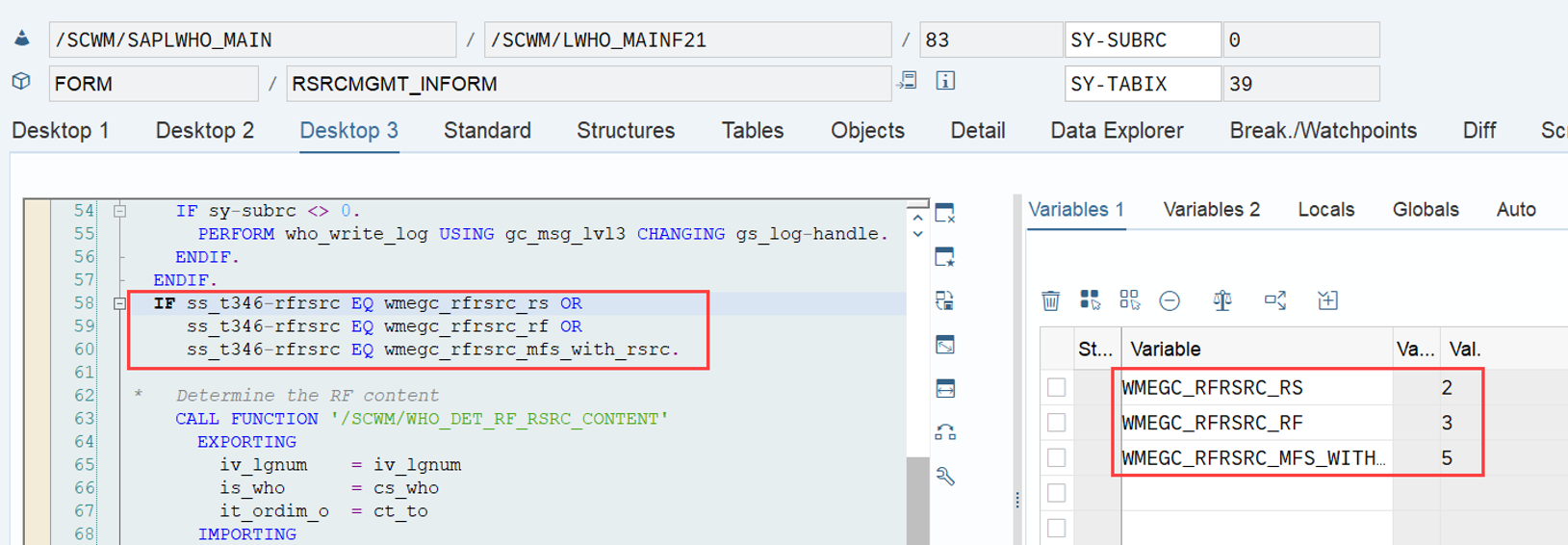
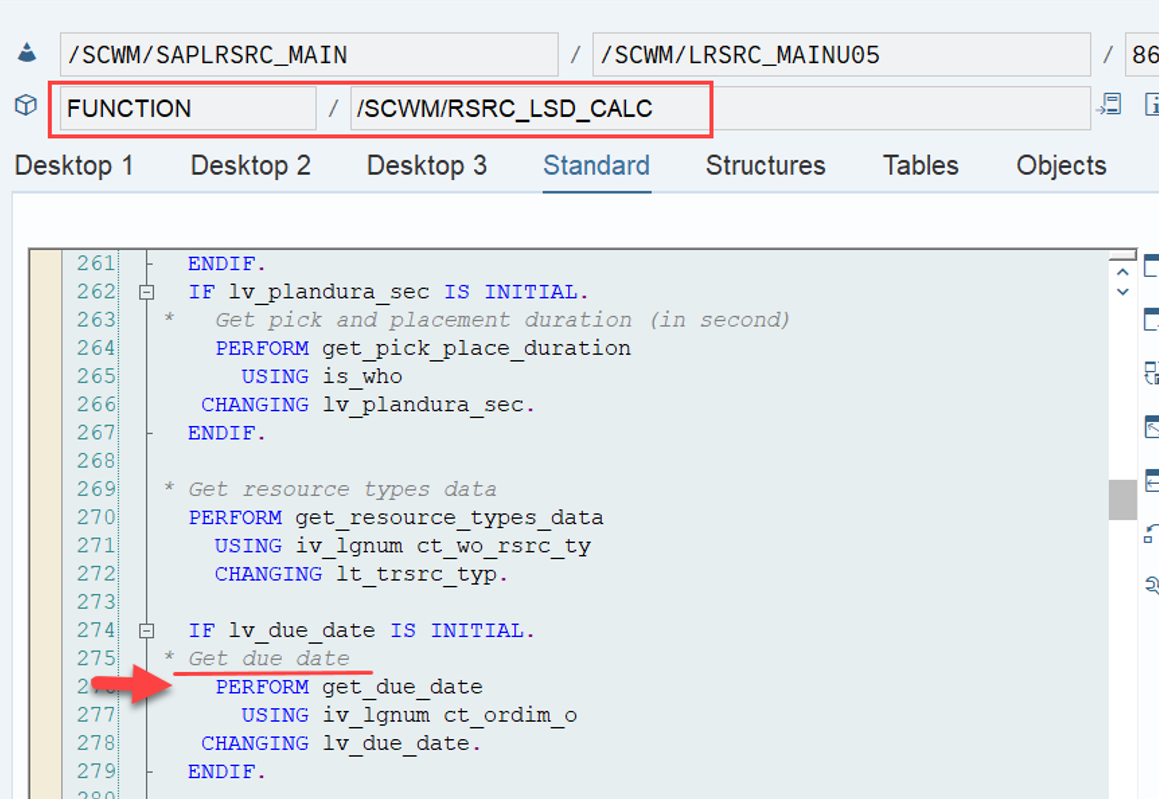
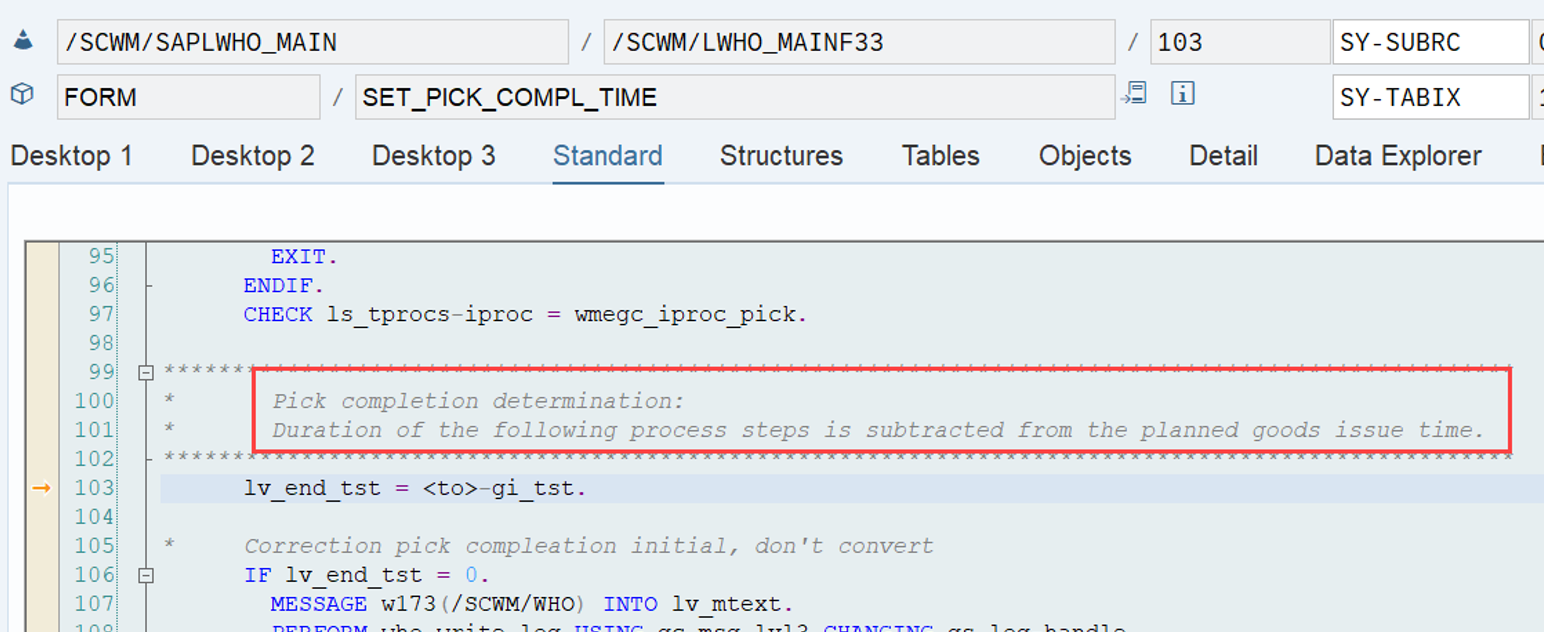
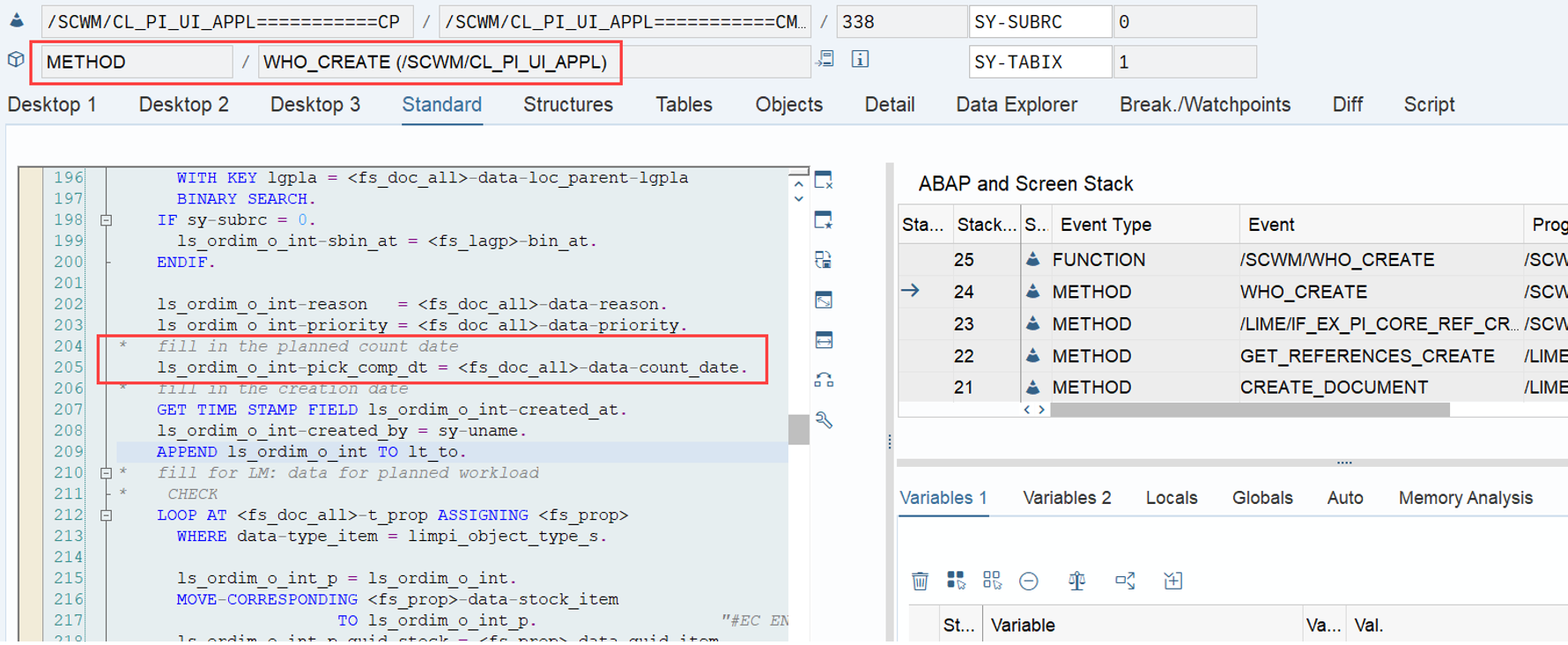
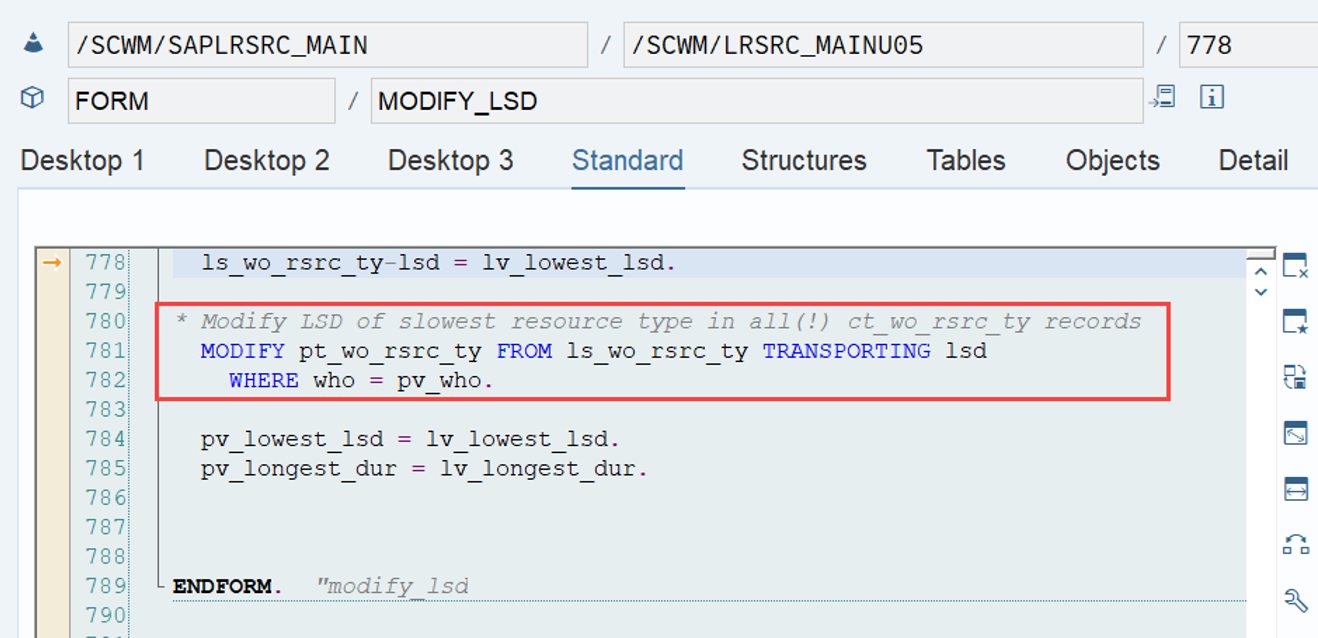
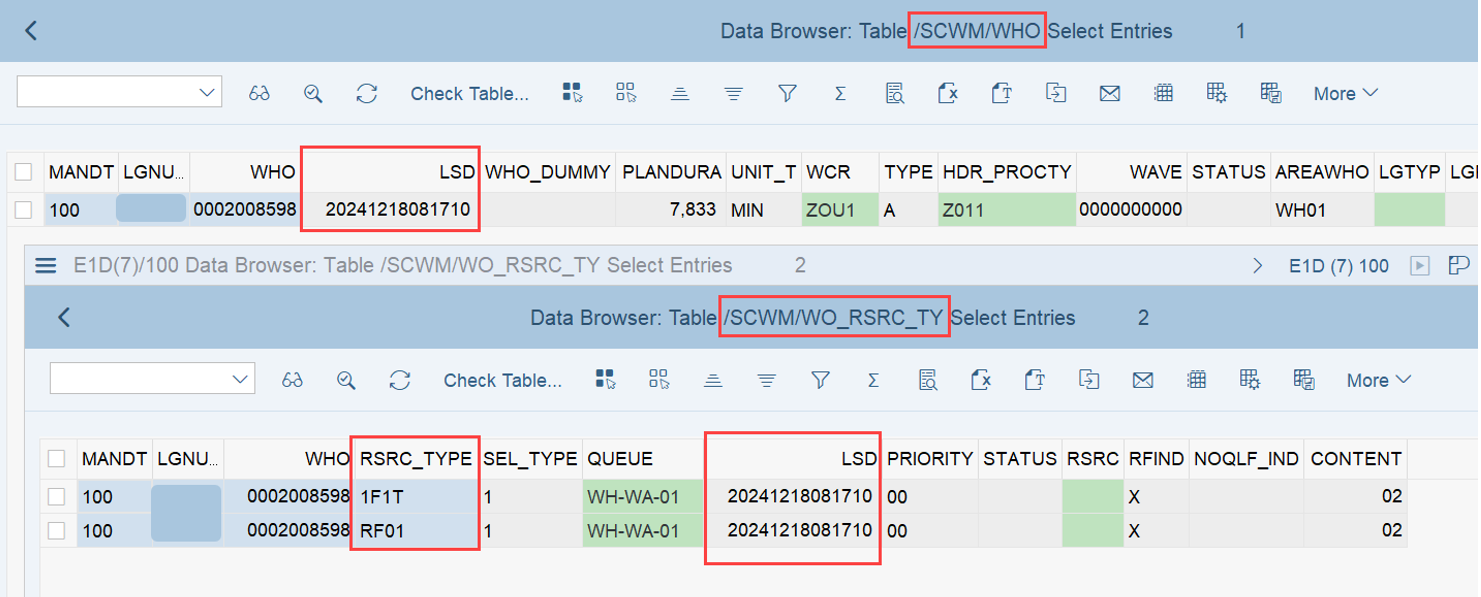
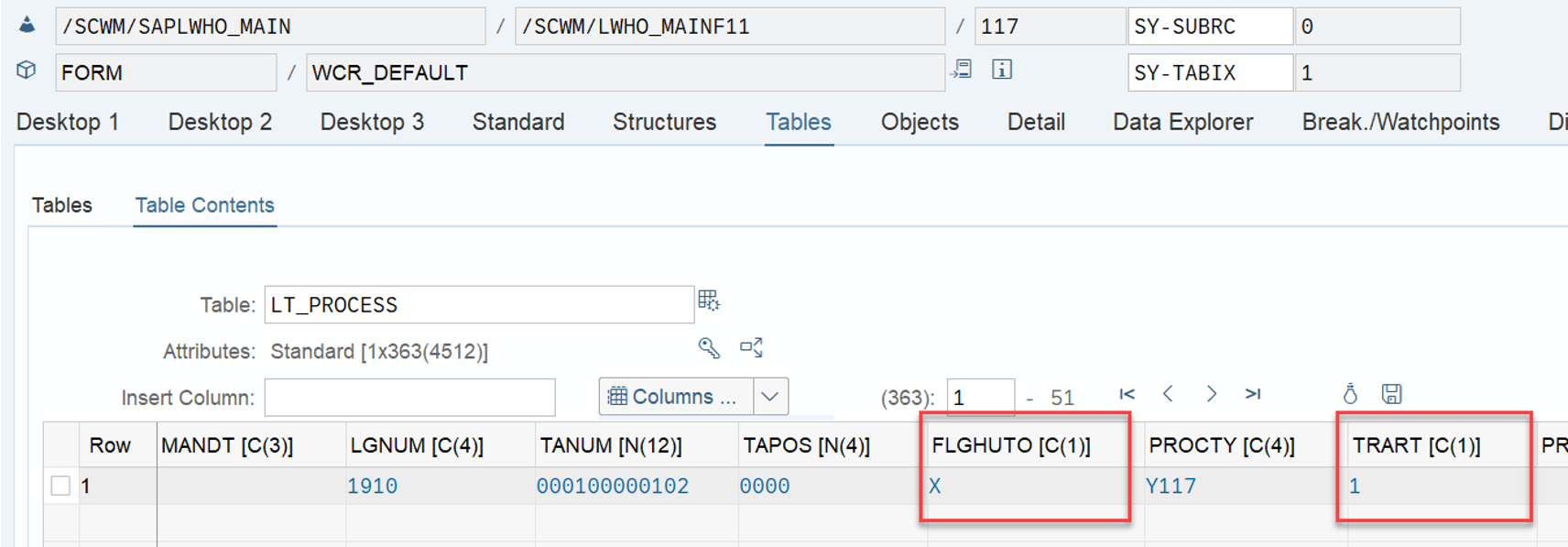
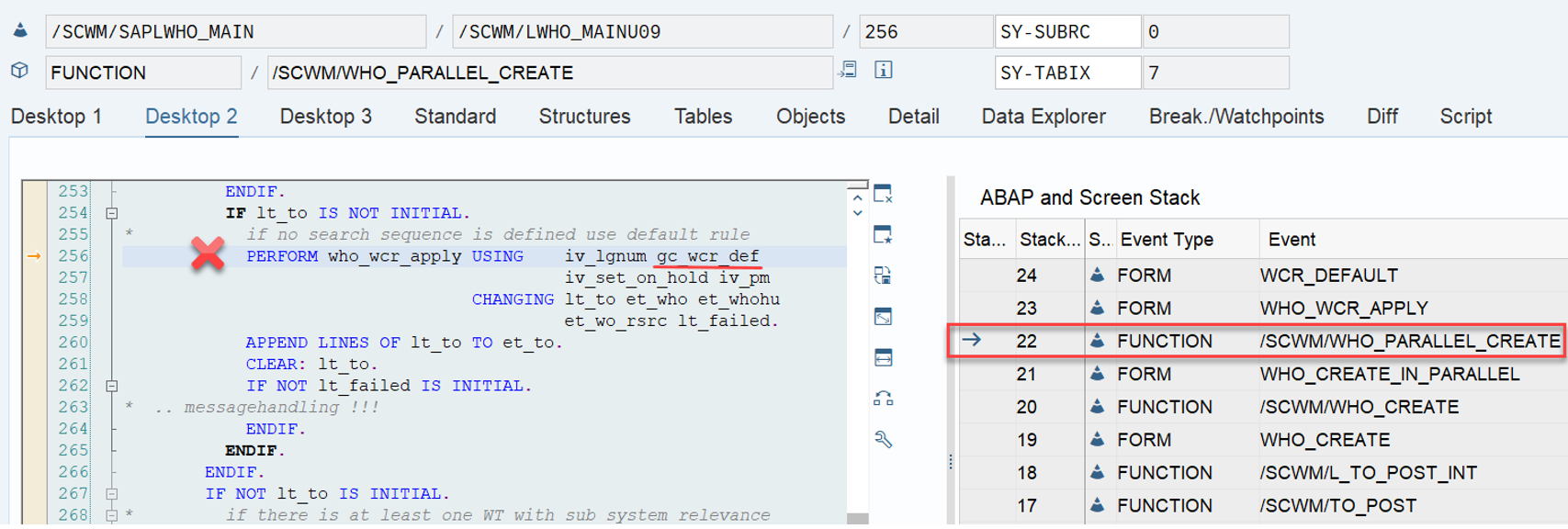
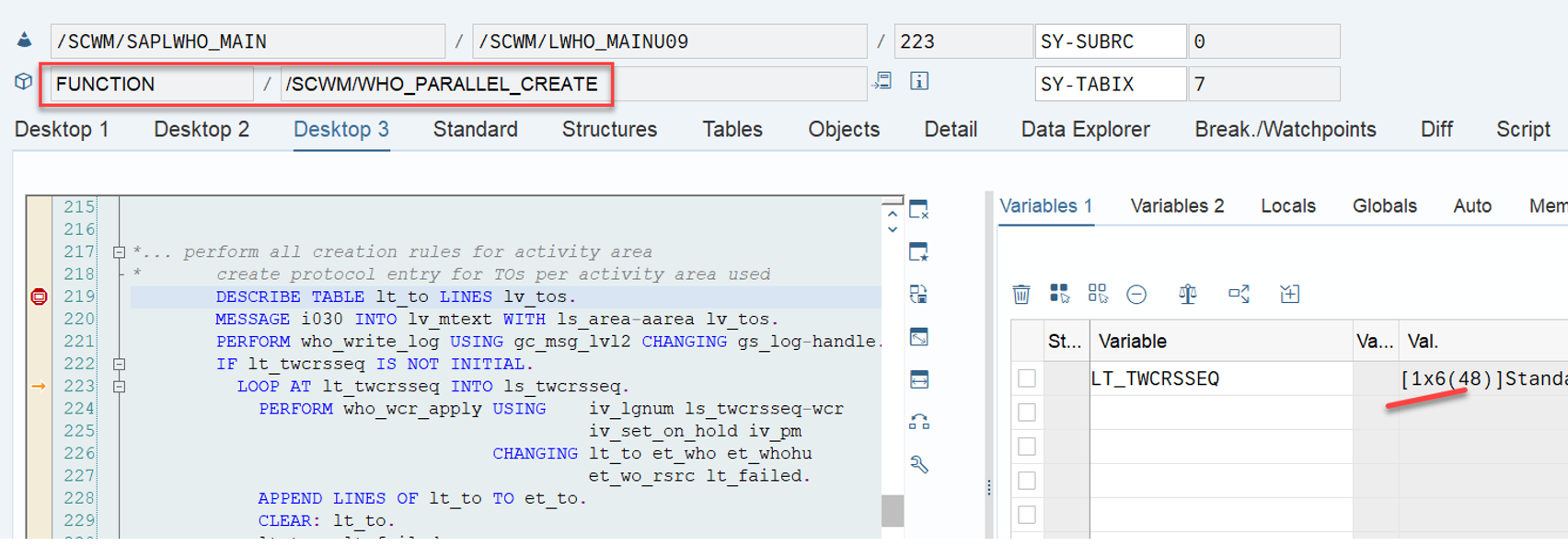
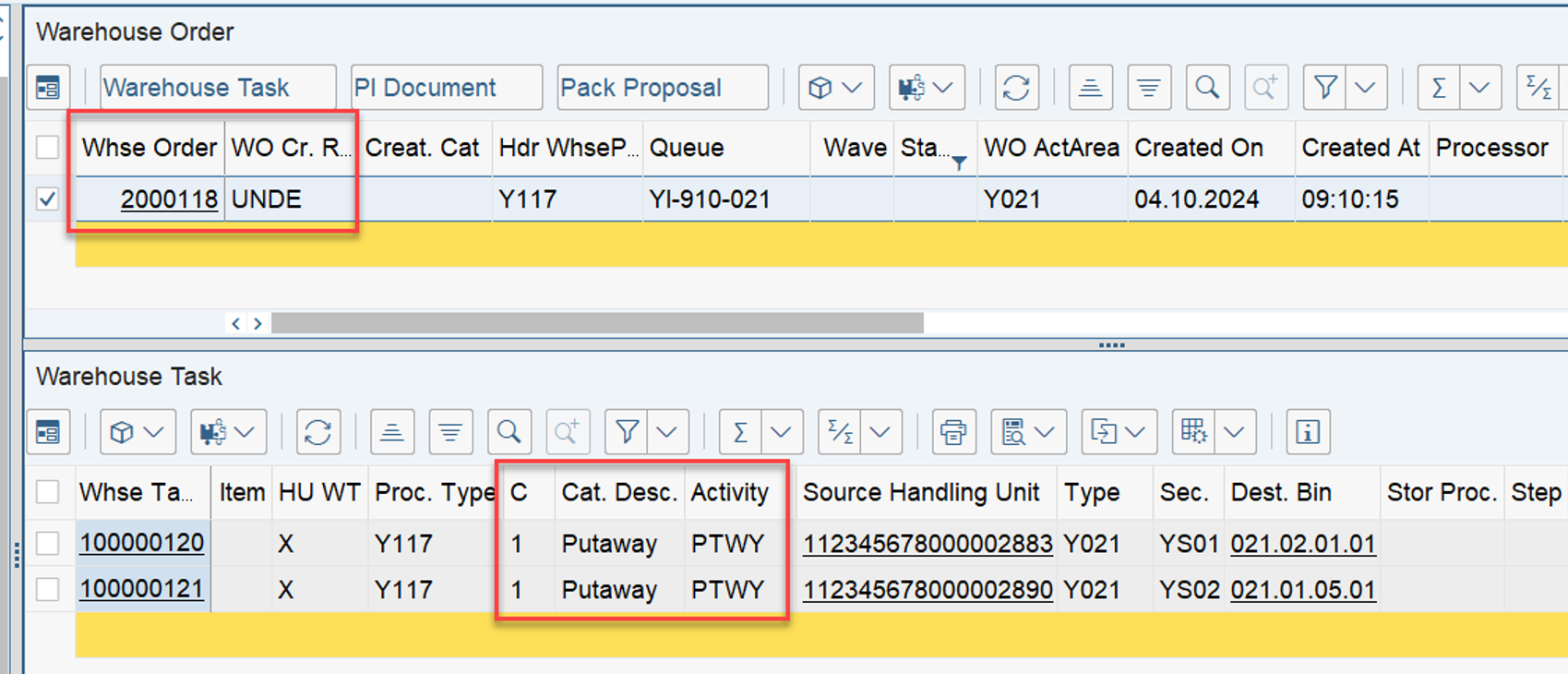
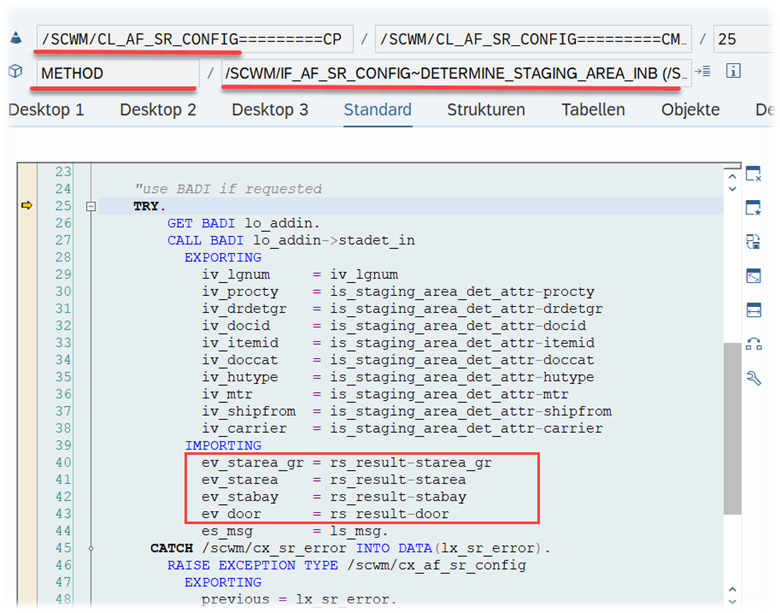
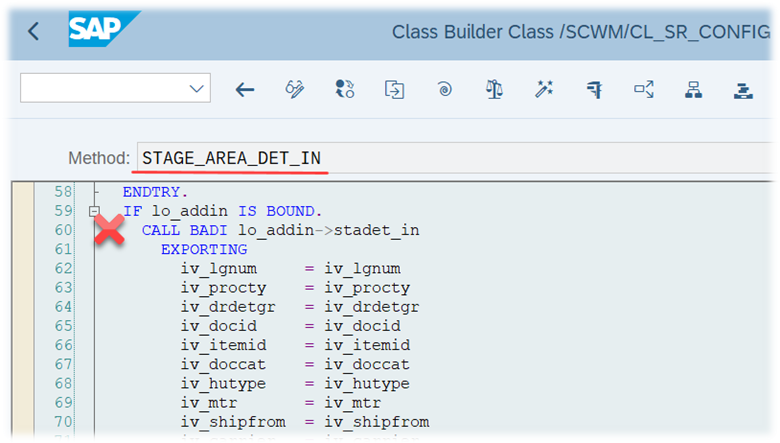
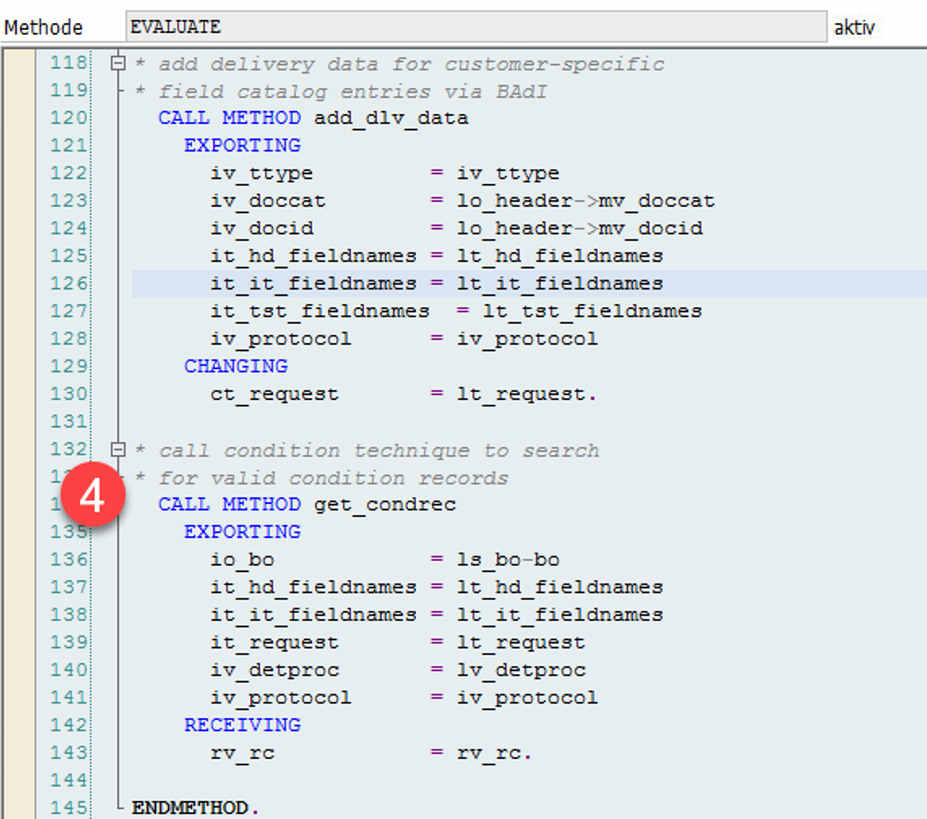
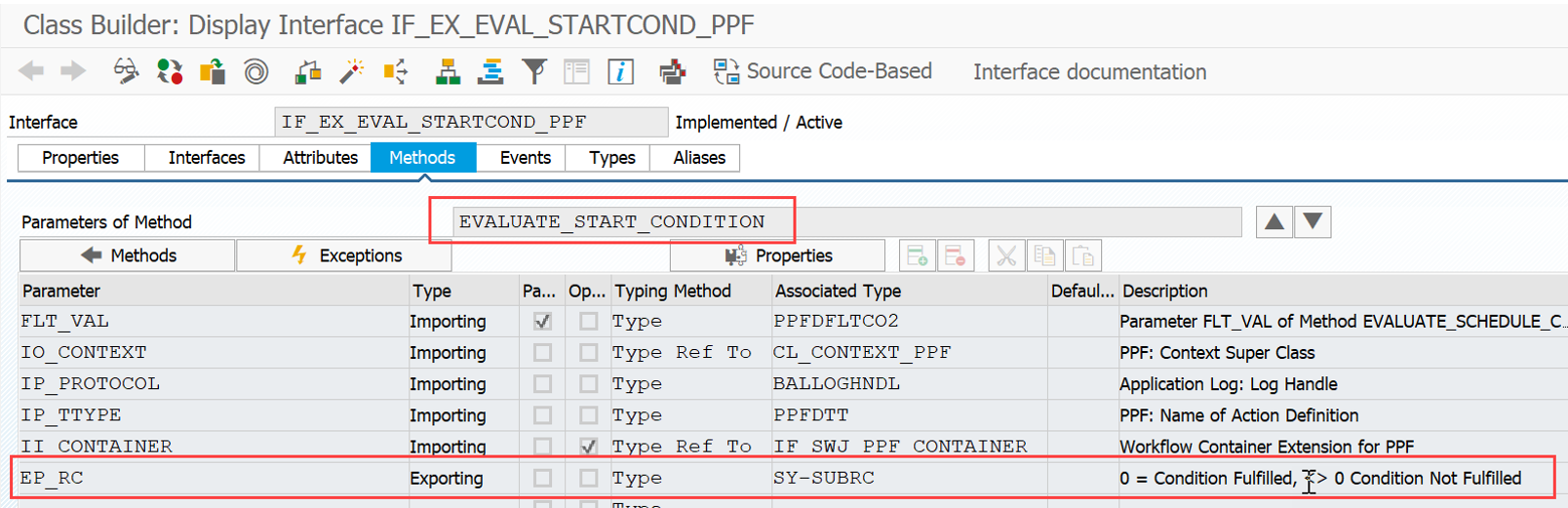
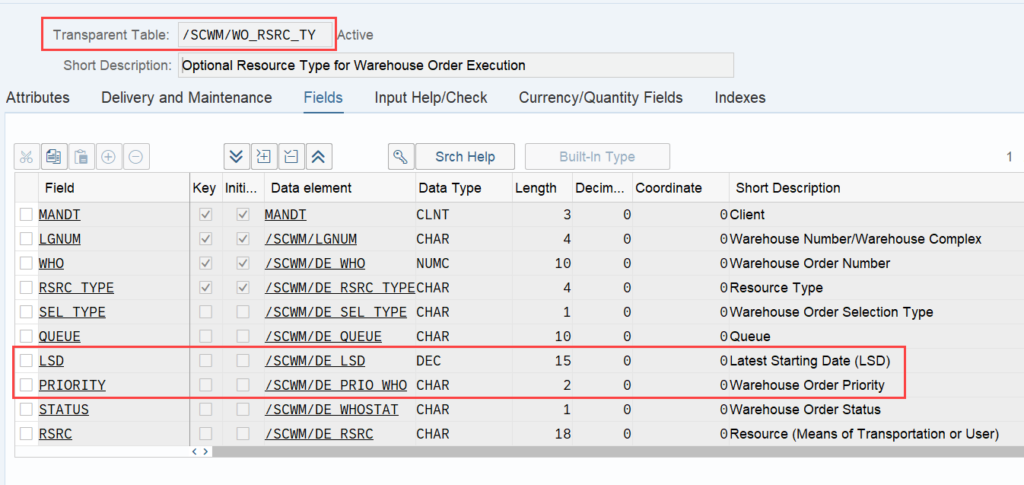
Important: Both values are calculated during warehouse order creation, well before the actual sorting occurs during warehouse order processing. Therefore, if you change your customization settings later, do not be surprised if nothing changes. Both values are saved in the table /SCWM/WO_RSRC_TY (the LSD is also saved in table /SCWM/WHO, but this table is not relevant for our context here). The calculation for both values is initiated by the function module FM /SCWM/RSRC_WHO_CREATE during warehouse order creation, which also calls FM /SCWM/WHO_RSRC_TYP_SET to write the result to the database.
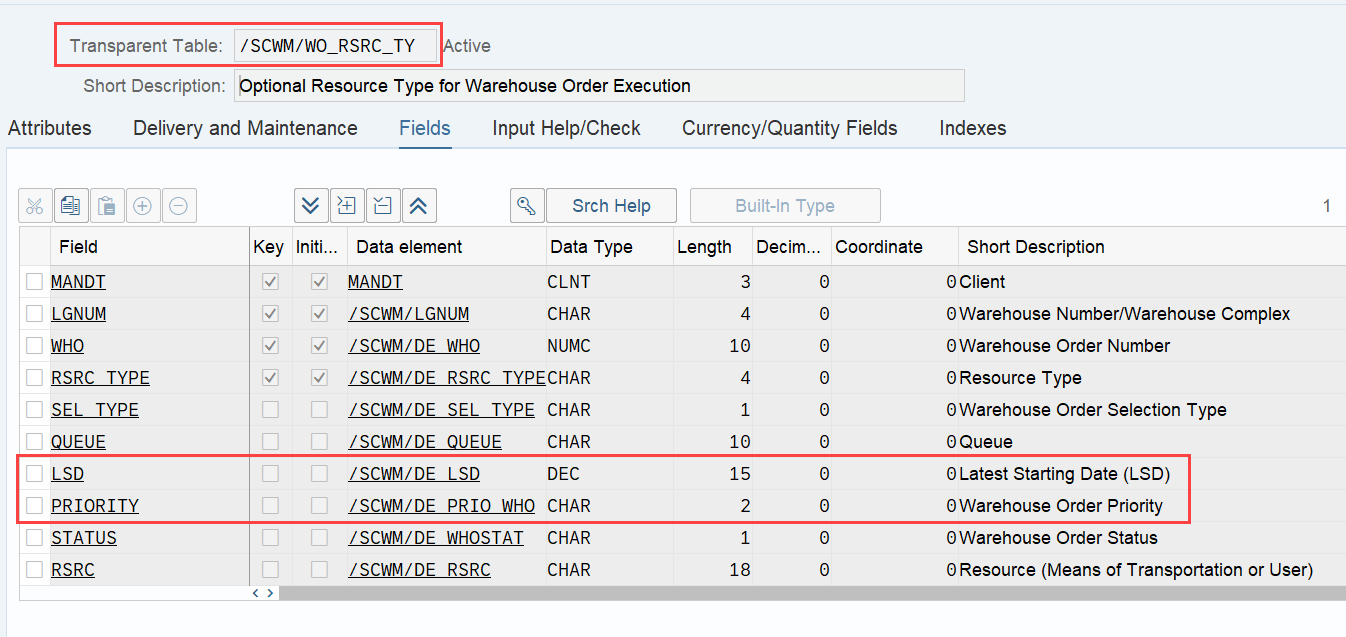
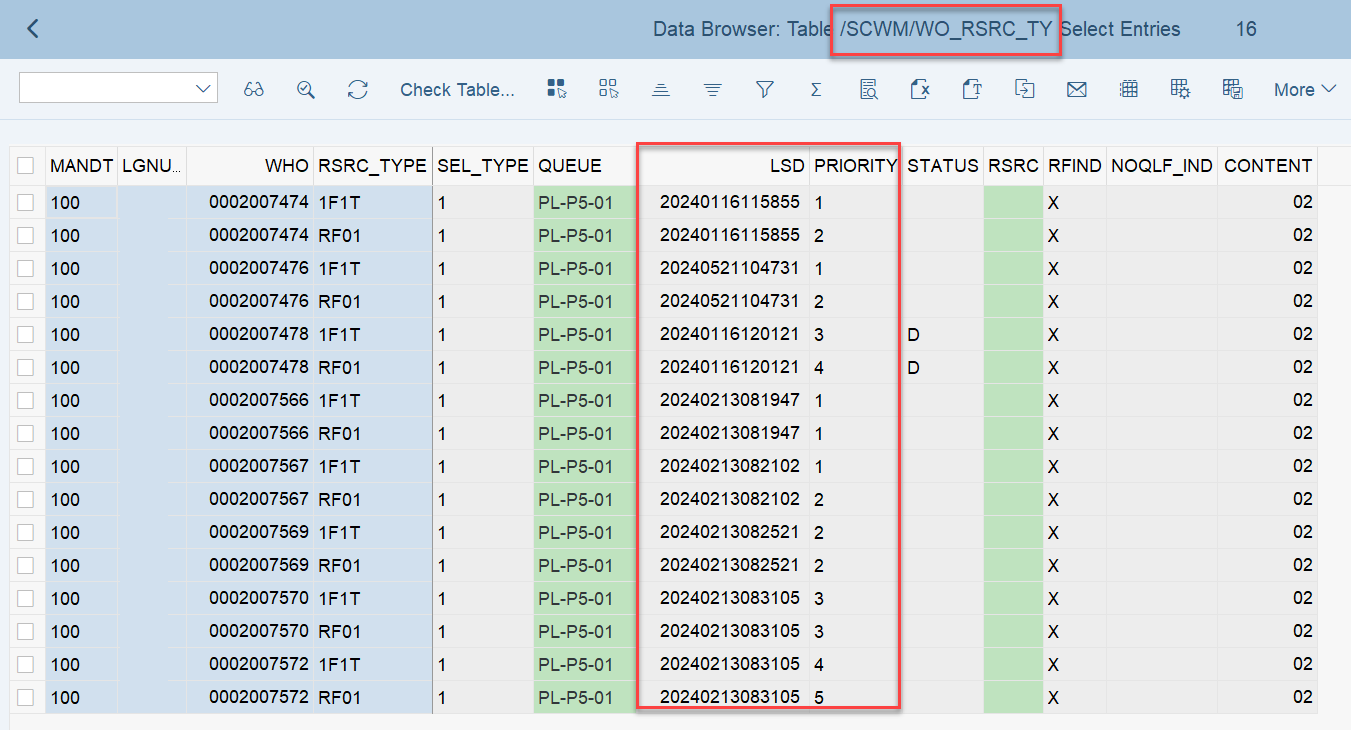
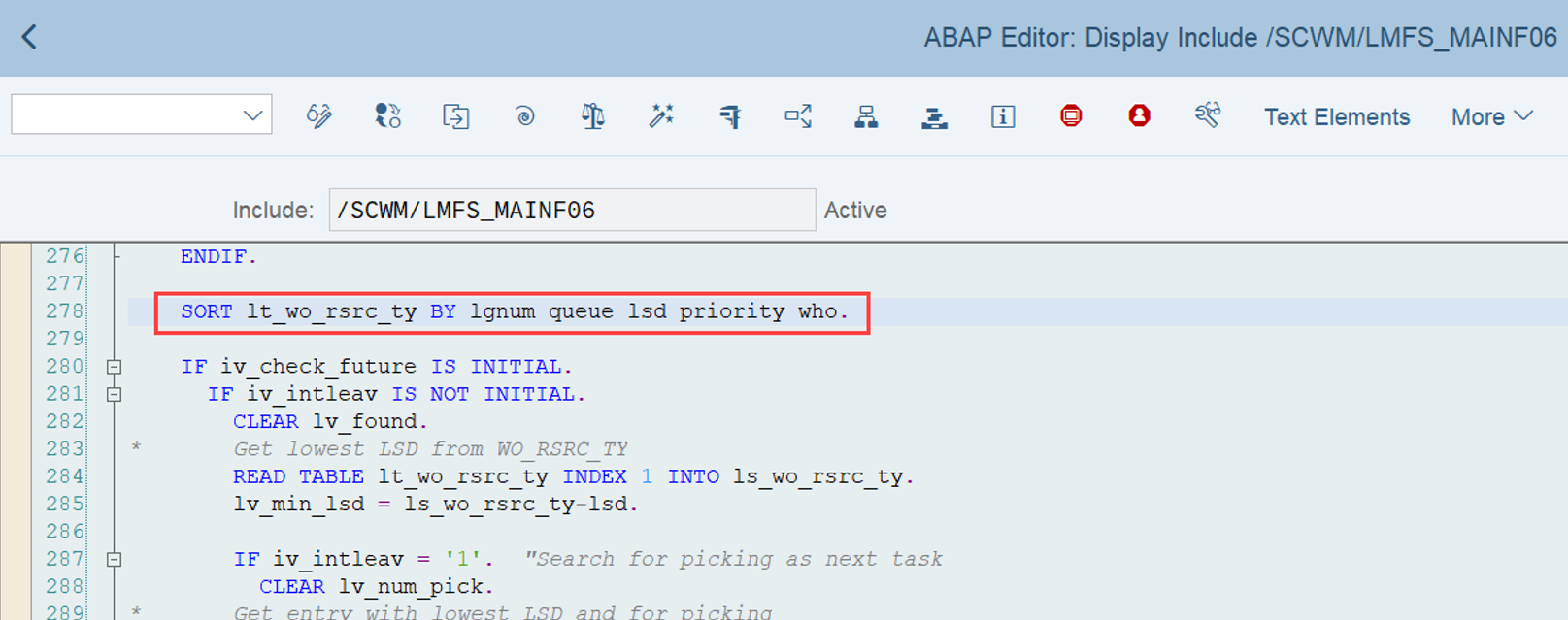
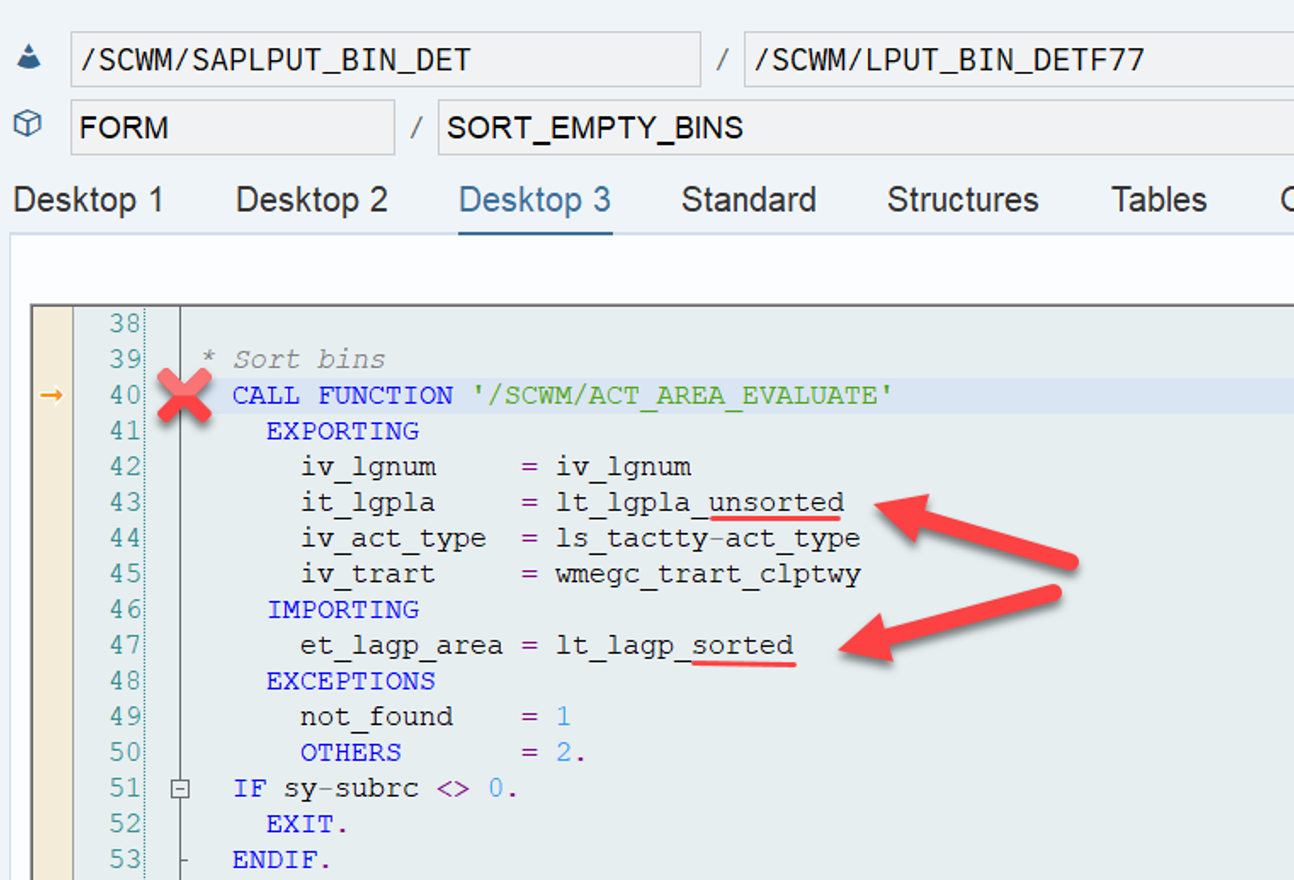
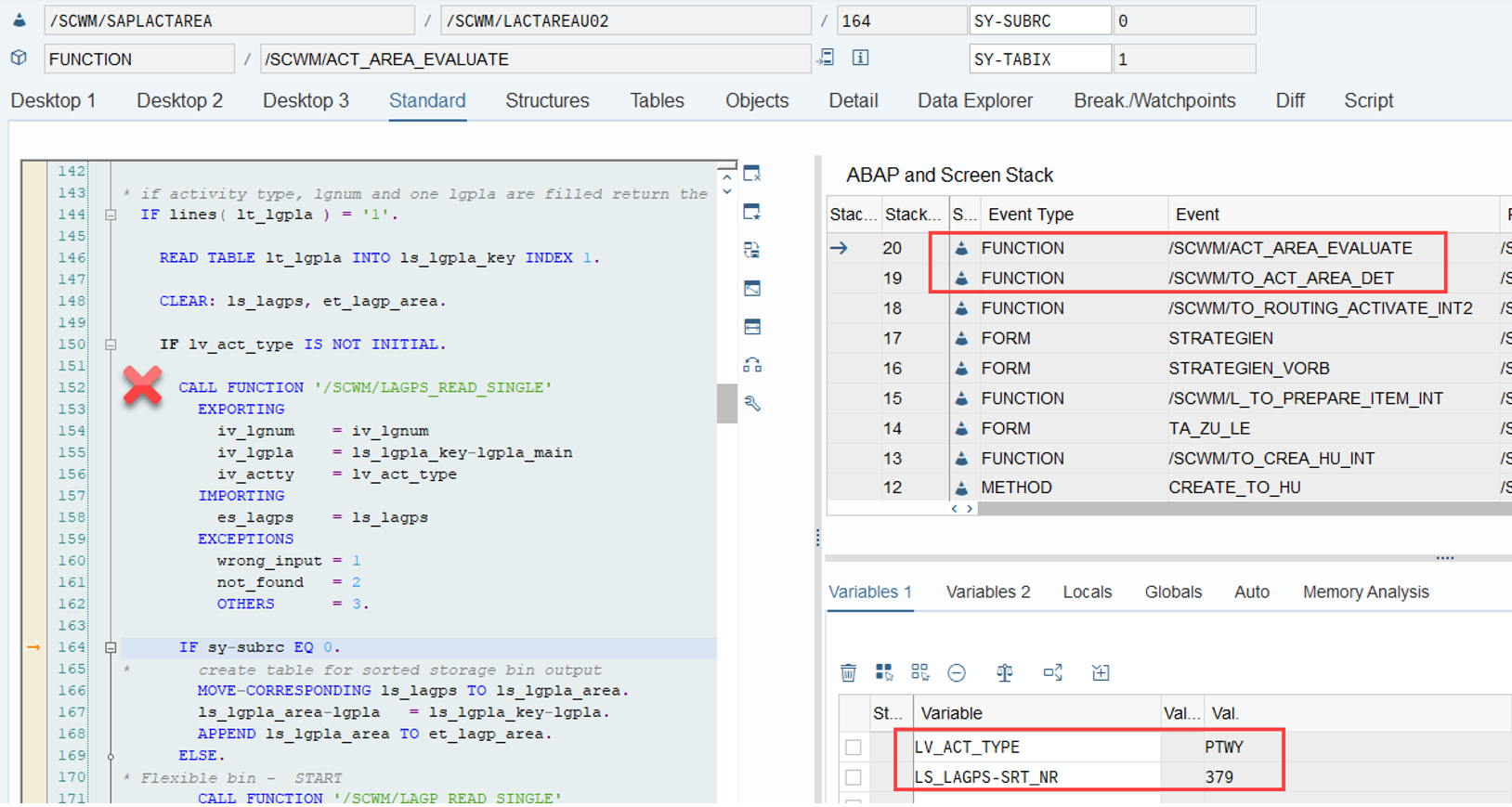
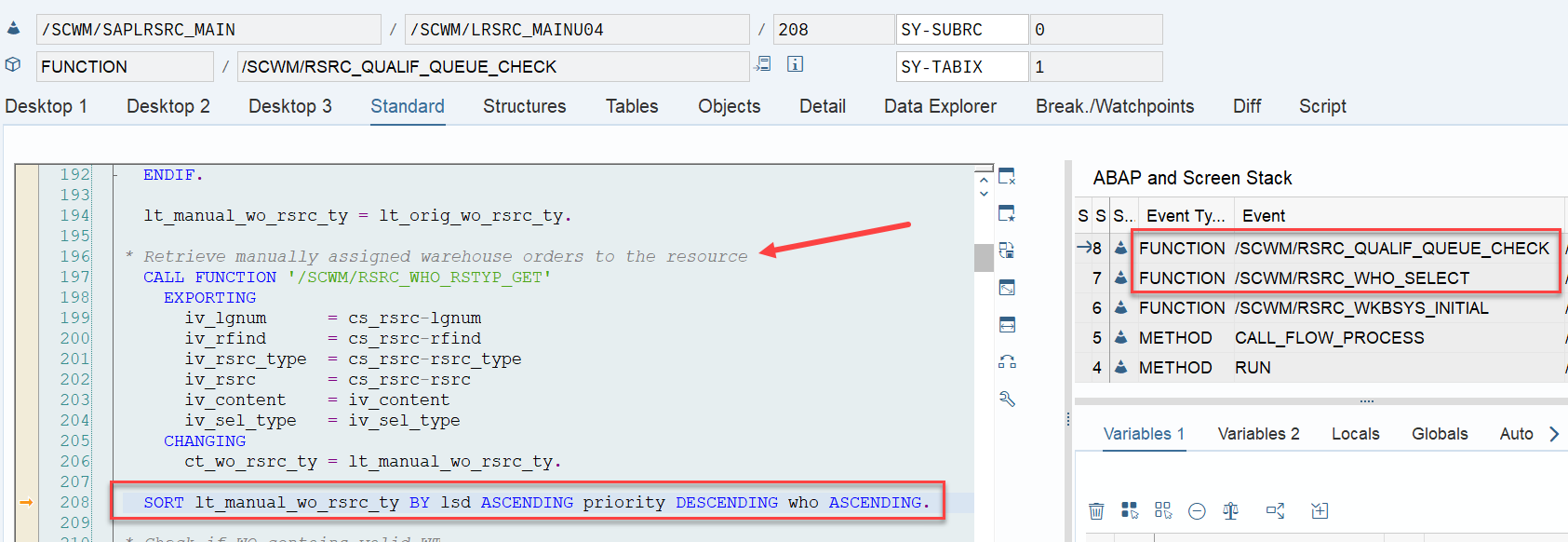
During warehouse order processing, EWM selects records from this table and sorts them accordingly. This process is executed via the function module /SCWM/RSRC_WHO_SELECT, which calls FM /SCWM/RSRC_QUALIF_QUEUE_CHECK, and subsequently calls FM /SCWM/RSRC_WHO_RSTYP_GET. This FM reads the table entries from /SCWM/WO_RSRC_TY before filtering and determining the applicable warehouse orders for the given resource type (details of which are not explained here)
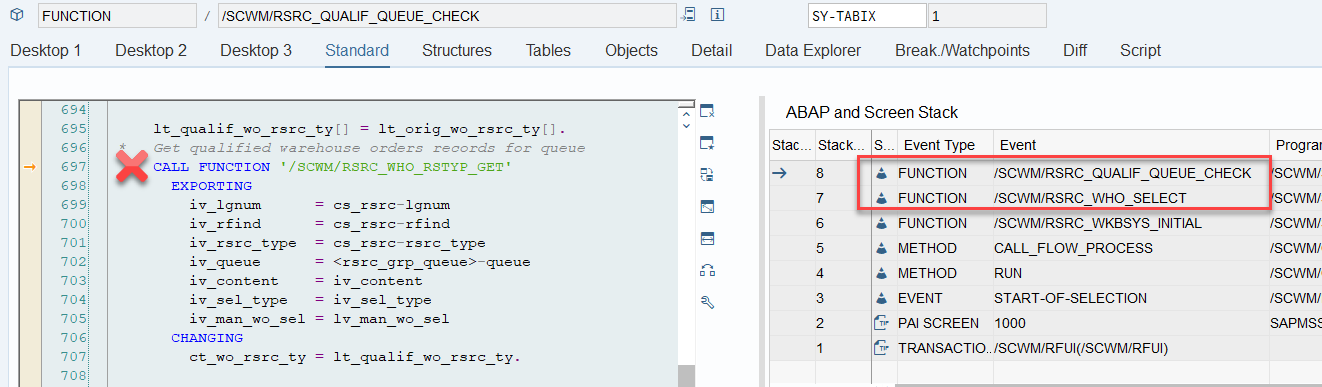
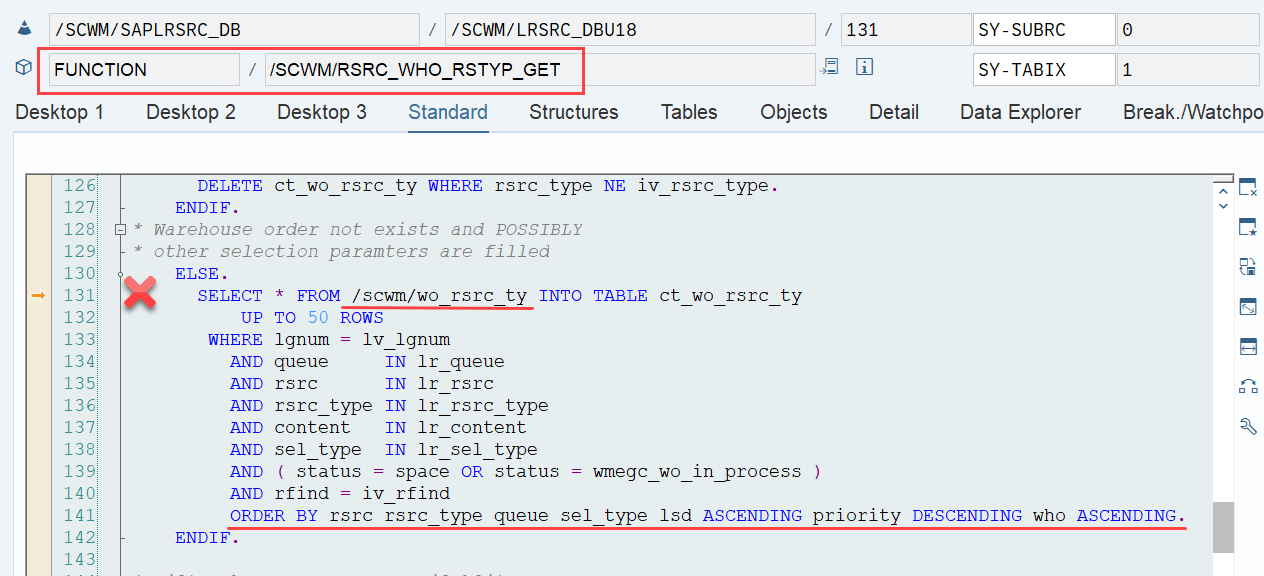
The same sorting is applied again a few lines later when the internal table is handed over to the calling function module FM /SCWM/RSRC_QUALIF_QUEUE_CHECK. This seems redundant, but there could be technical reasons for it (Is a developer amongst you able to explain the technical reason for sorting two times here in the comments of the corresponding video!?).
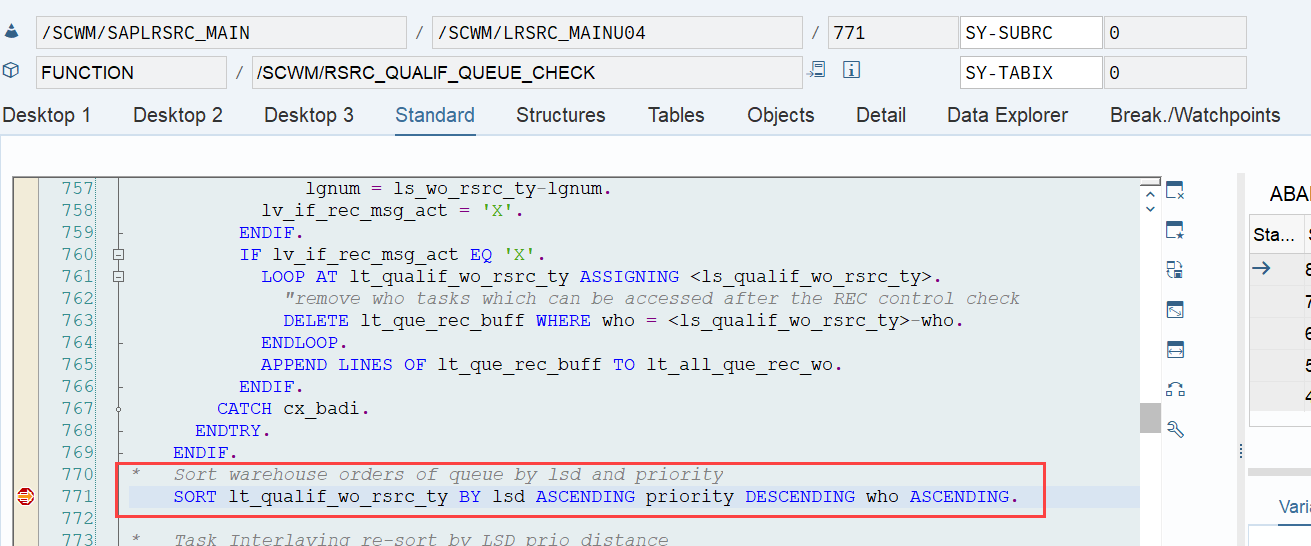
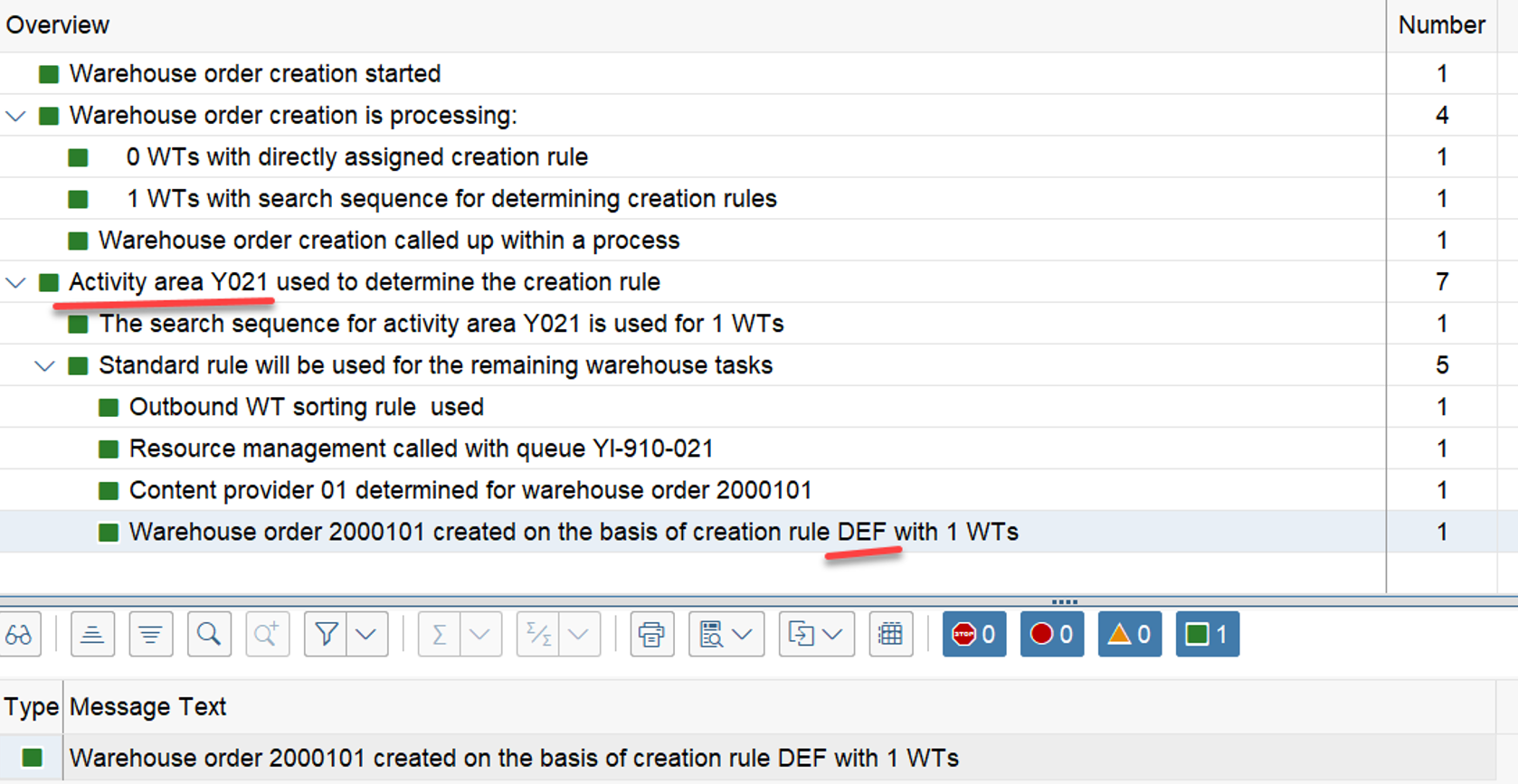
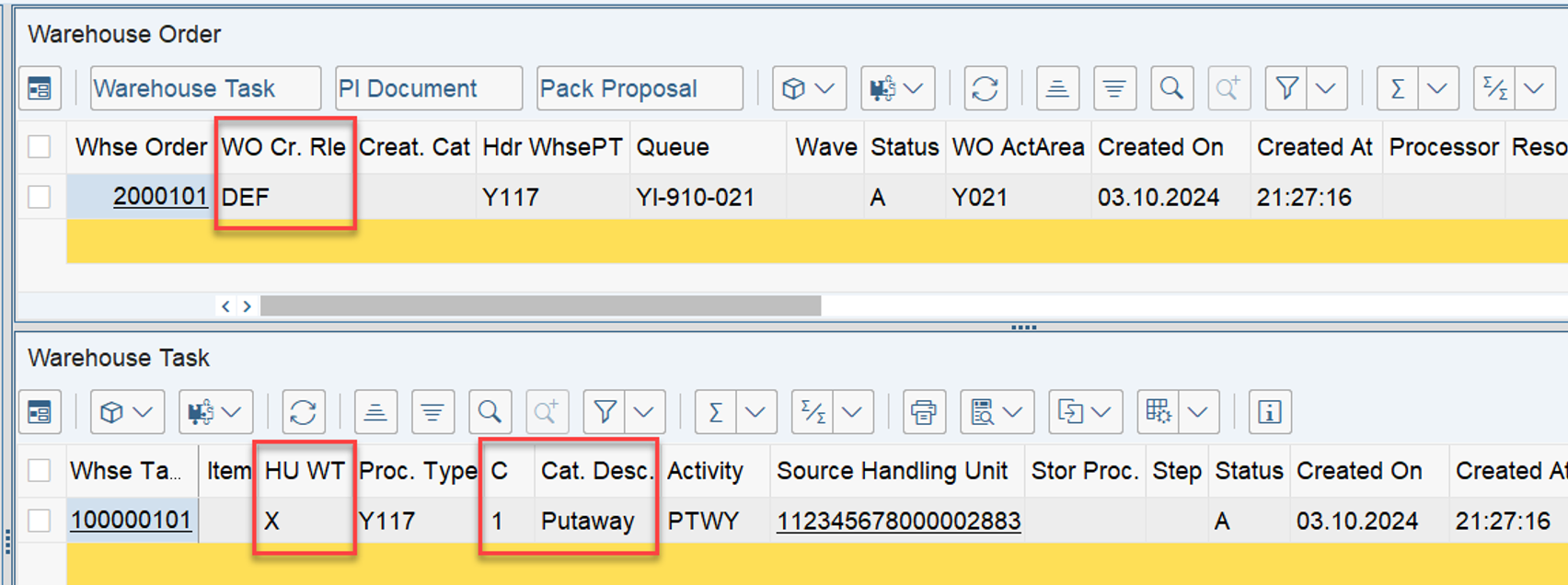
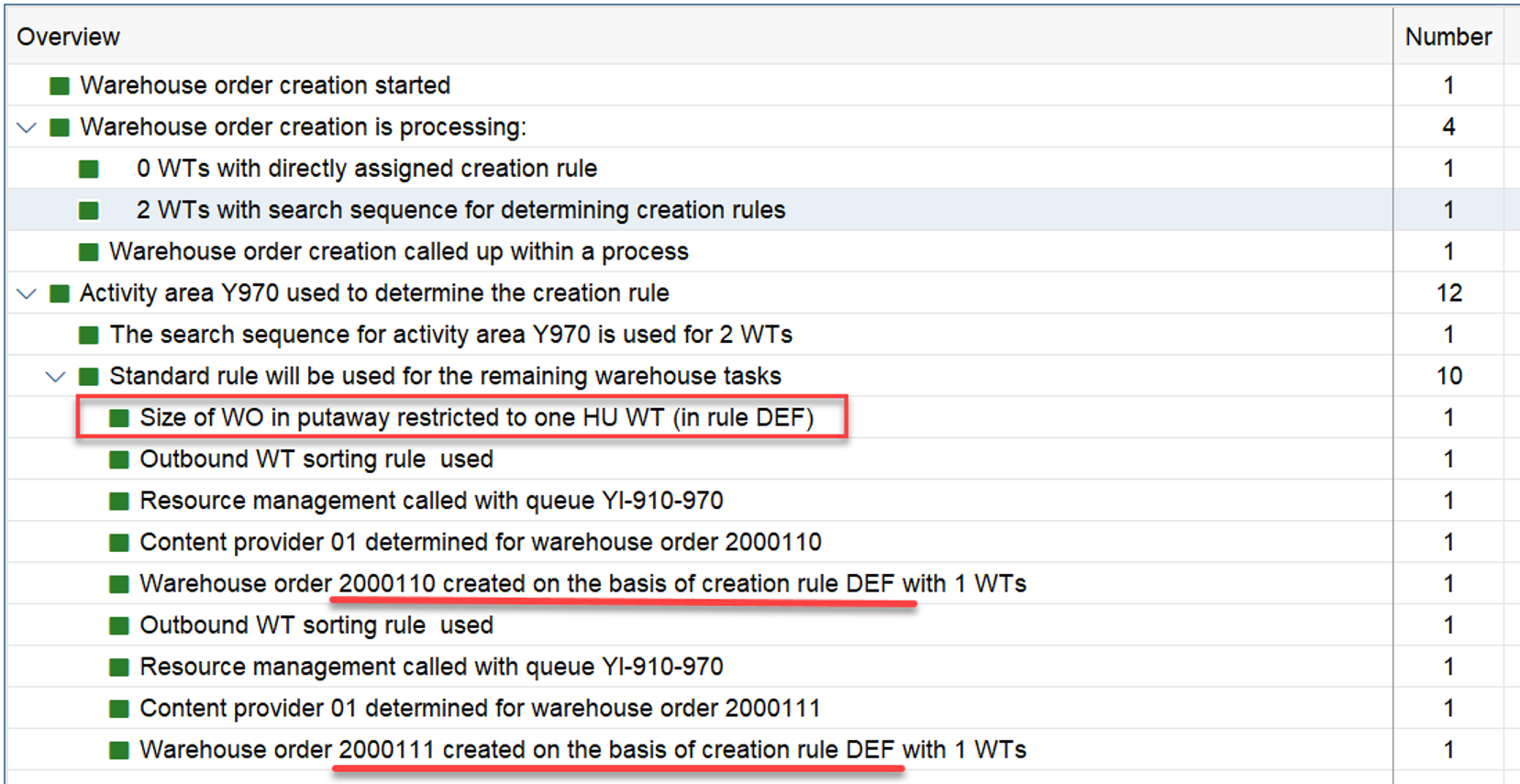
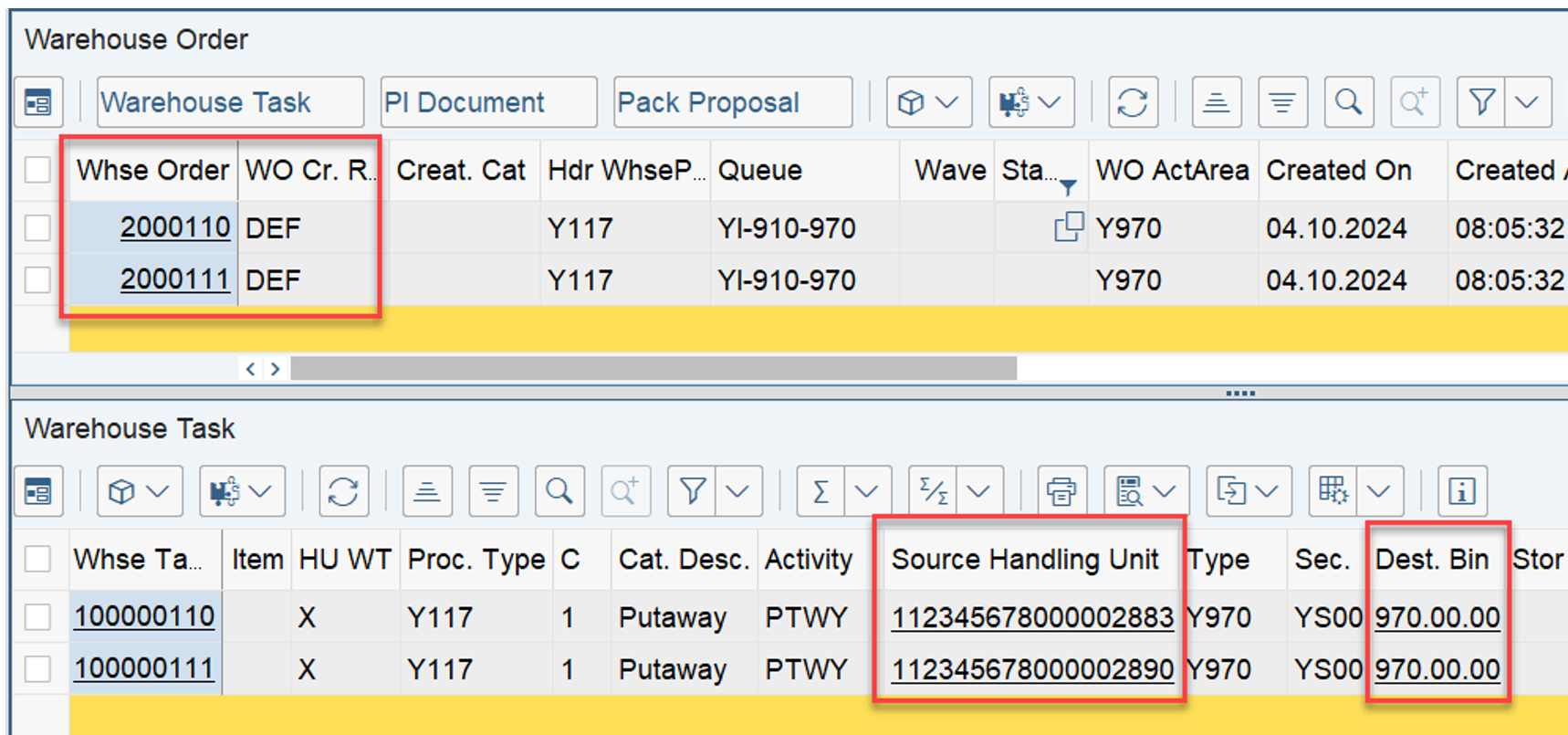
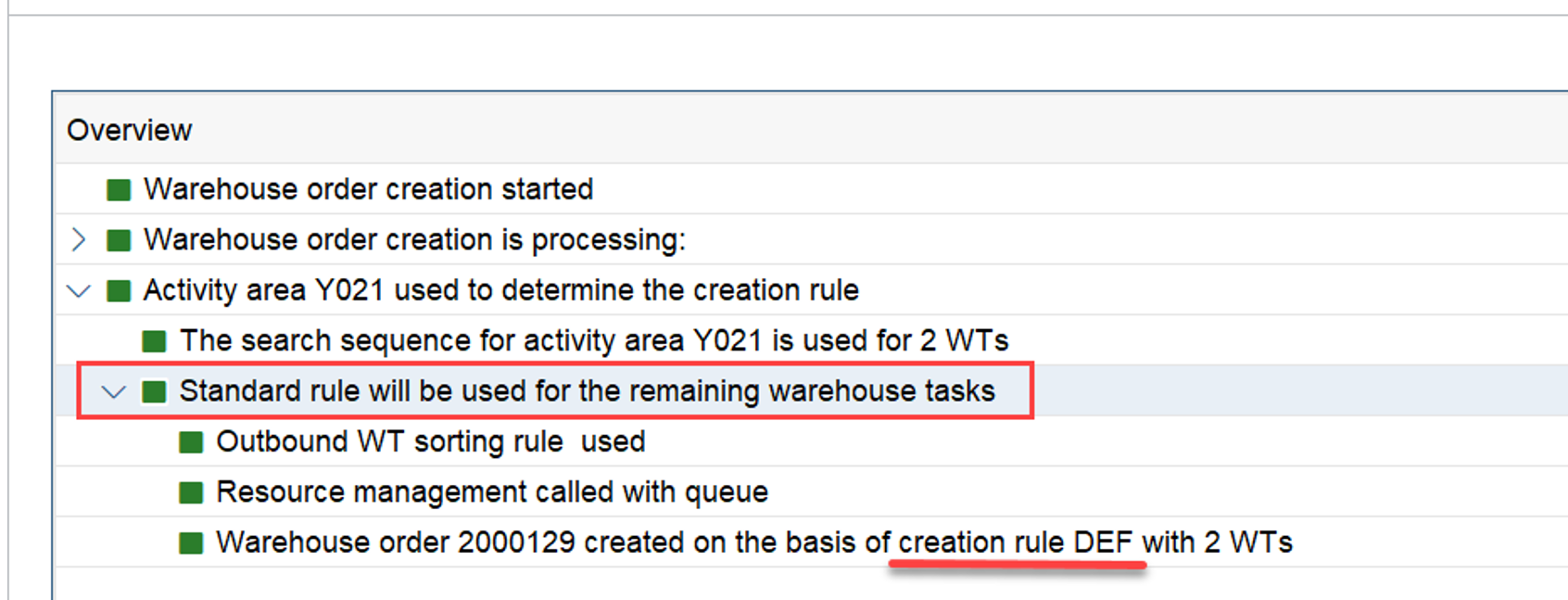
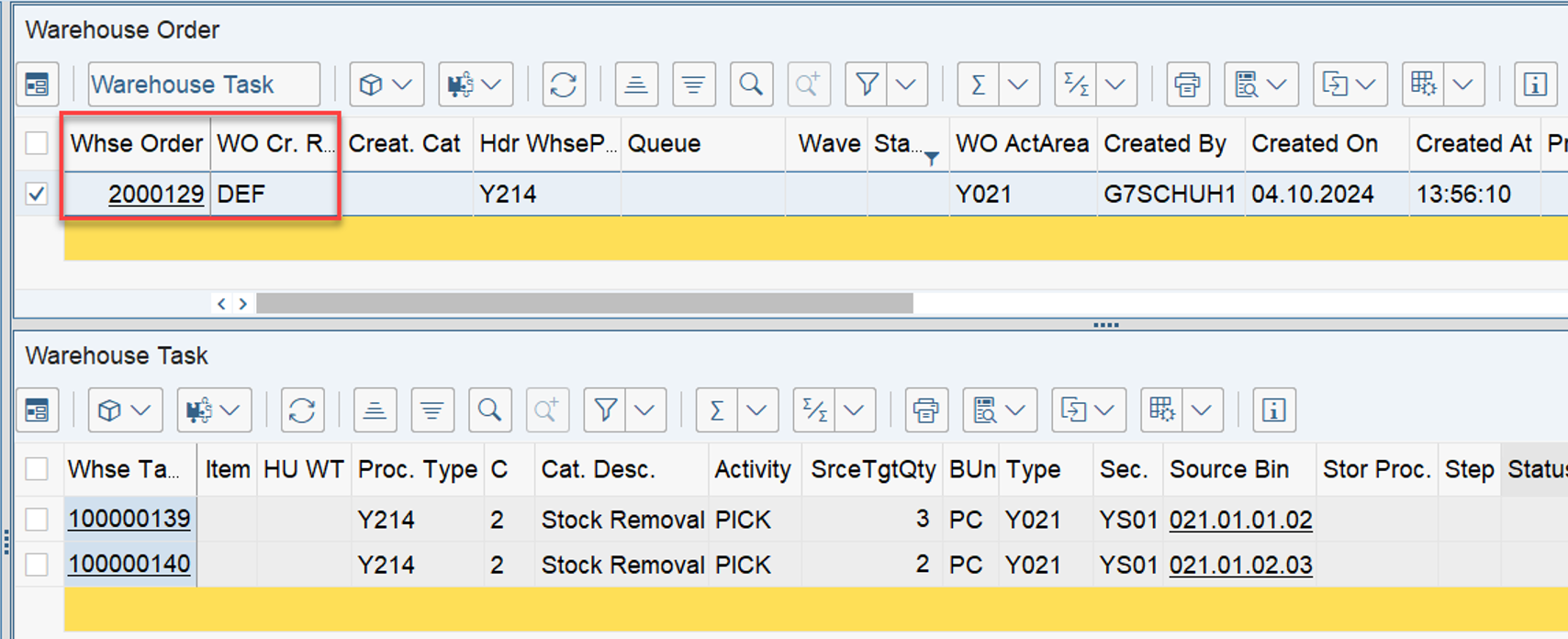
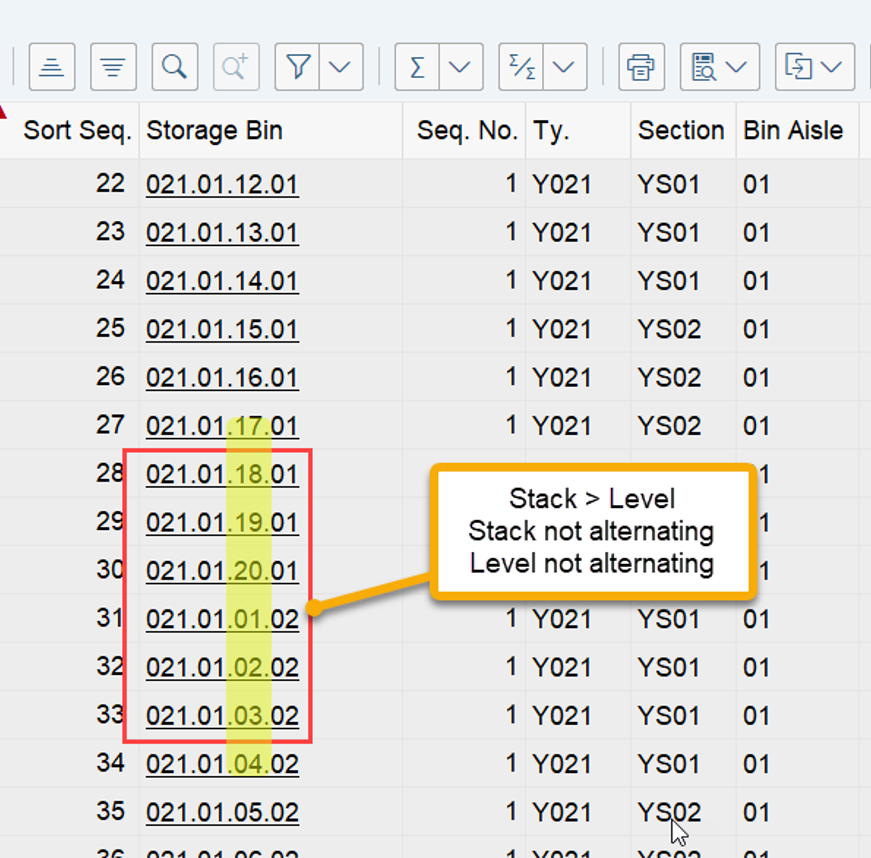
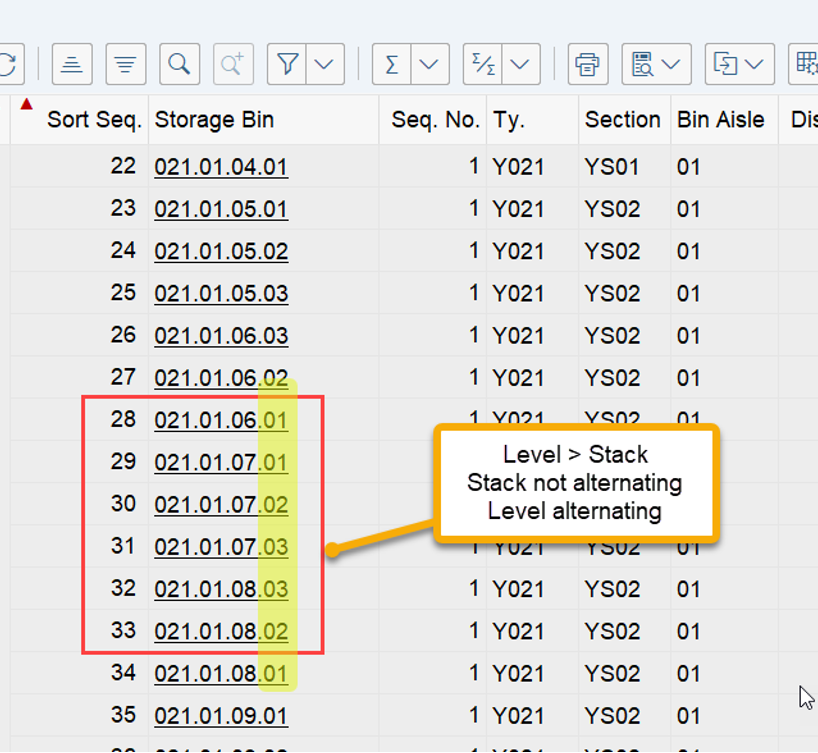
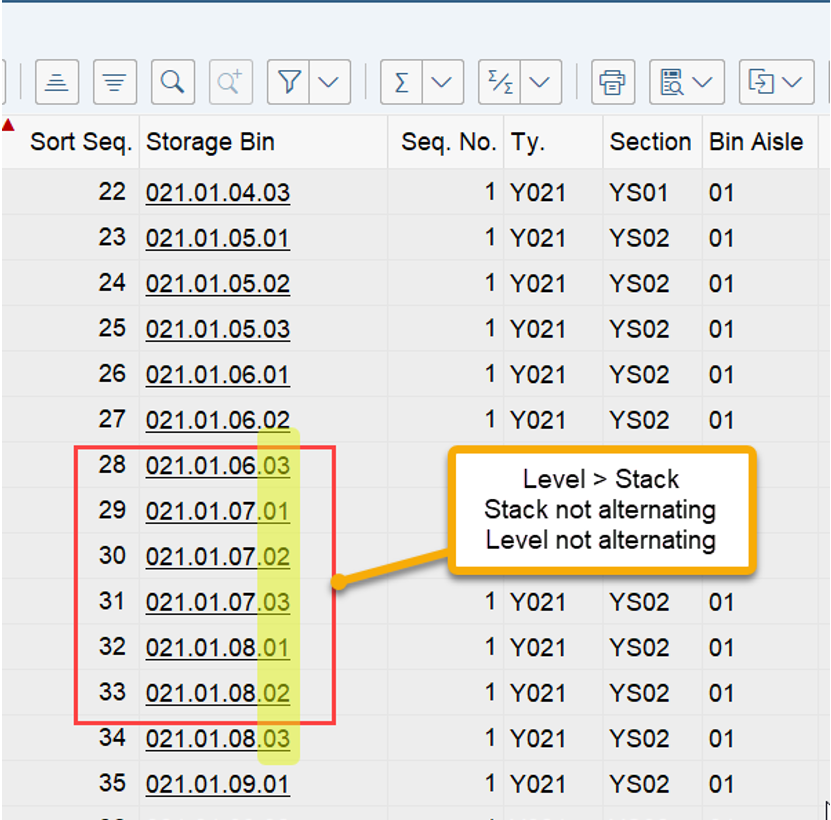
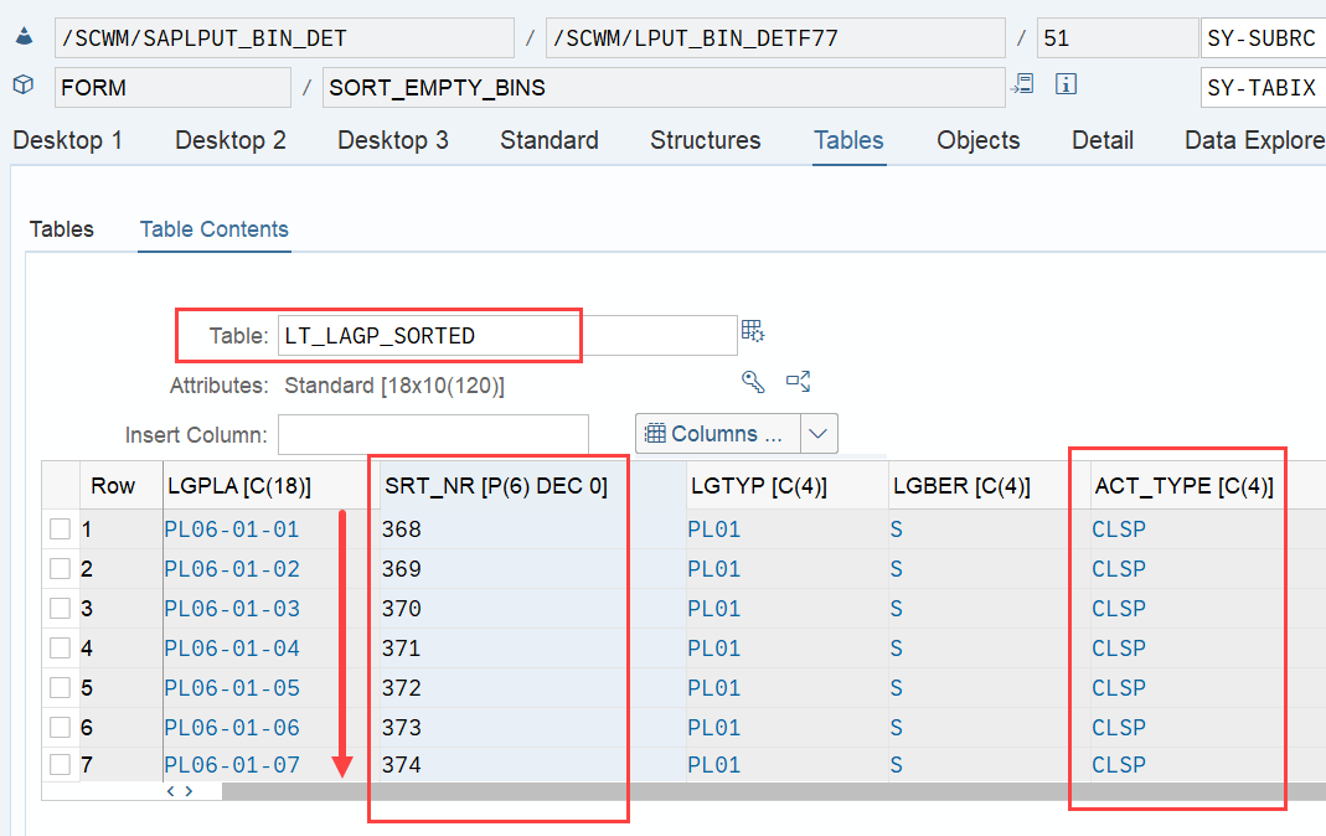
The example below highlights the way of sorting, based on the 3 values listed above:
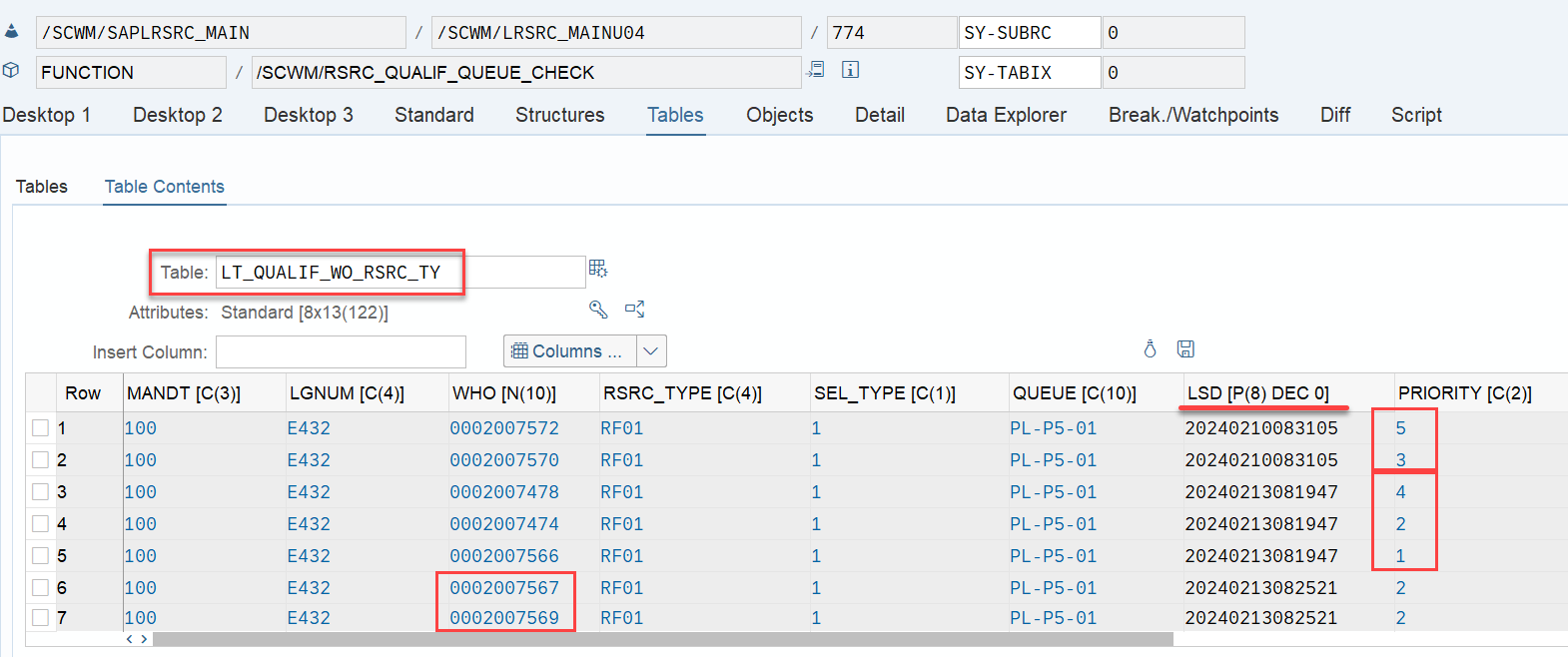
At the end, EWM just proceeds with the first WO from the list/table.
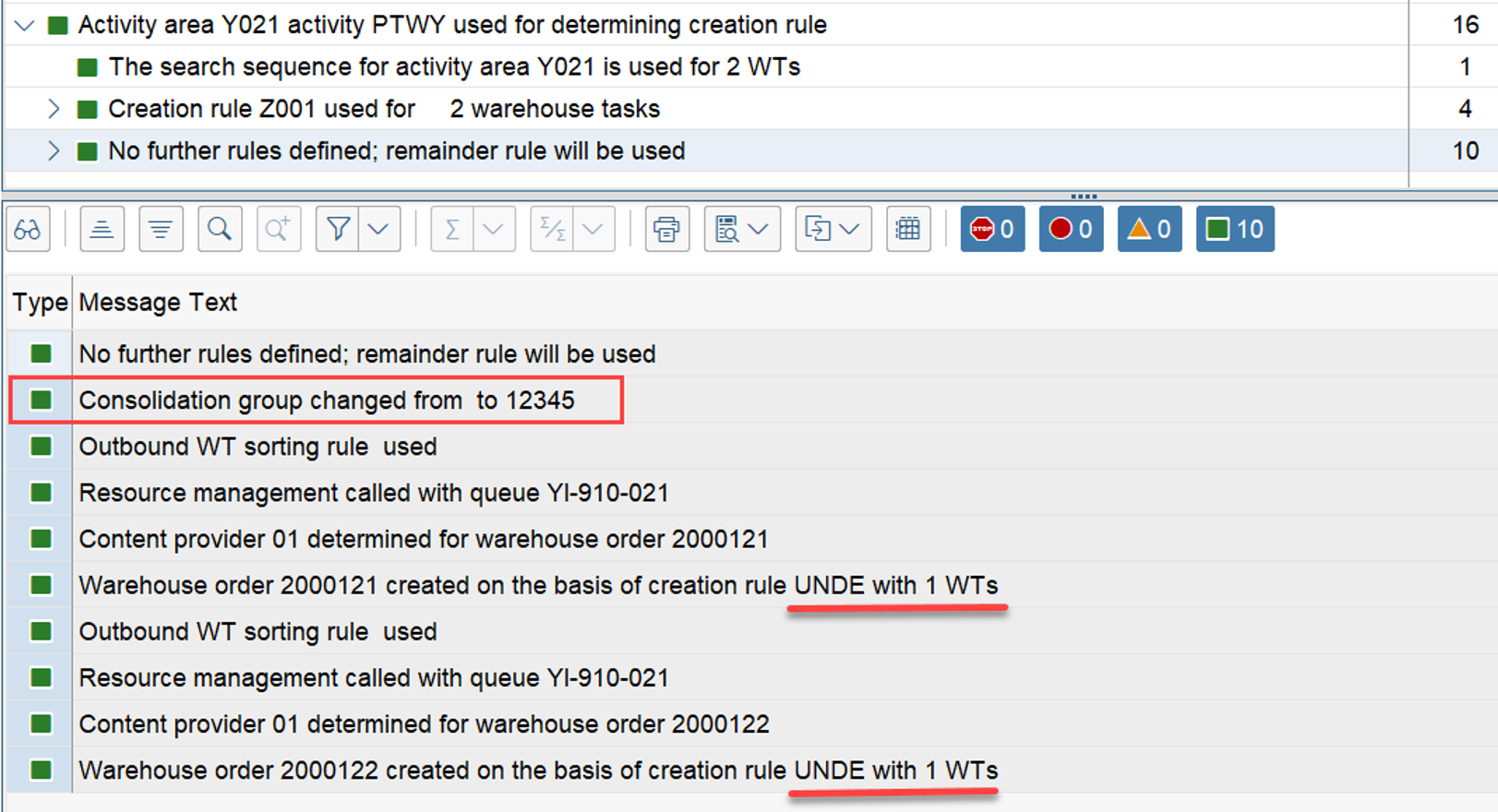
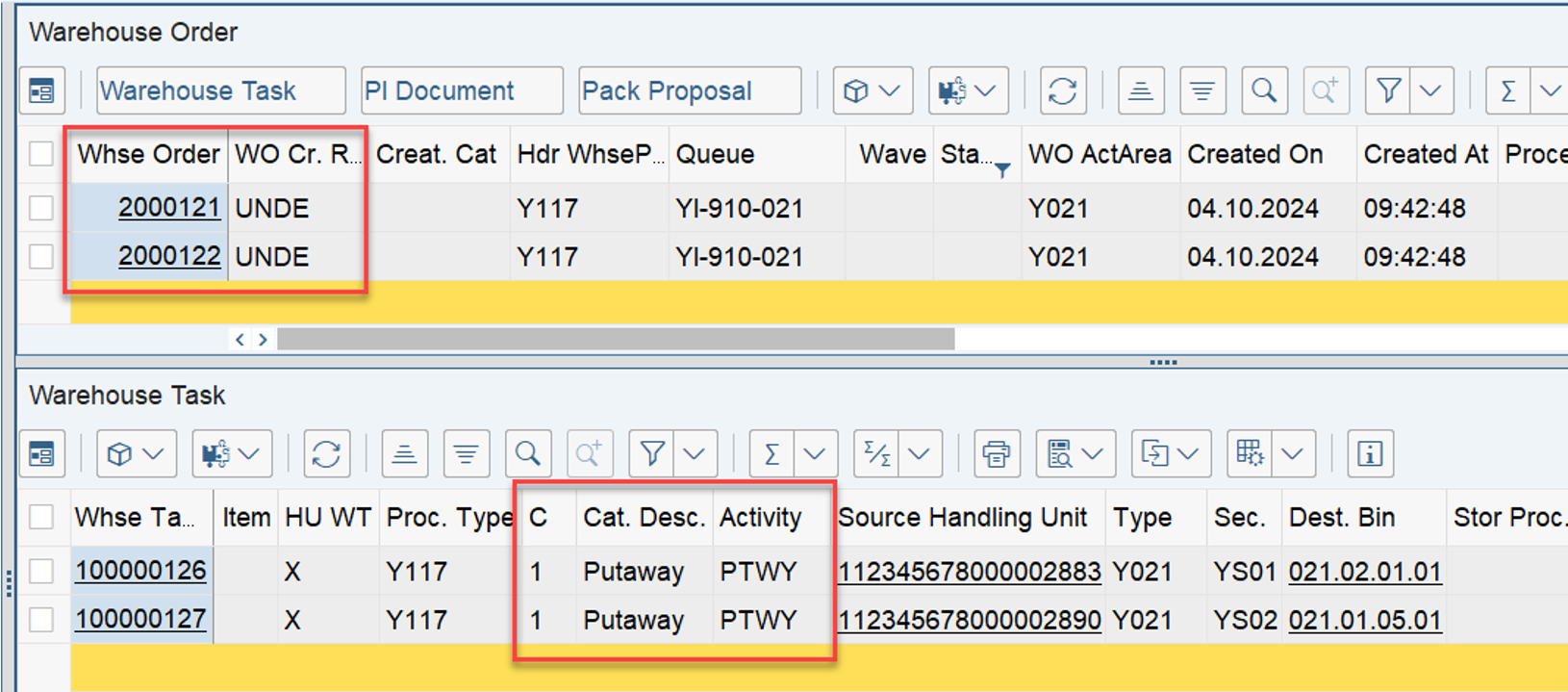
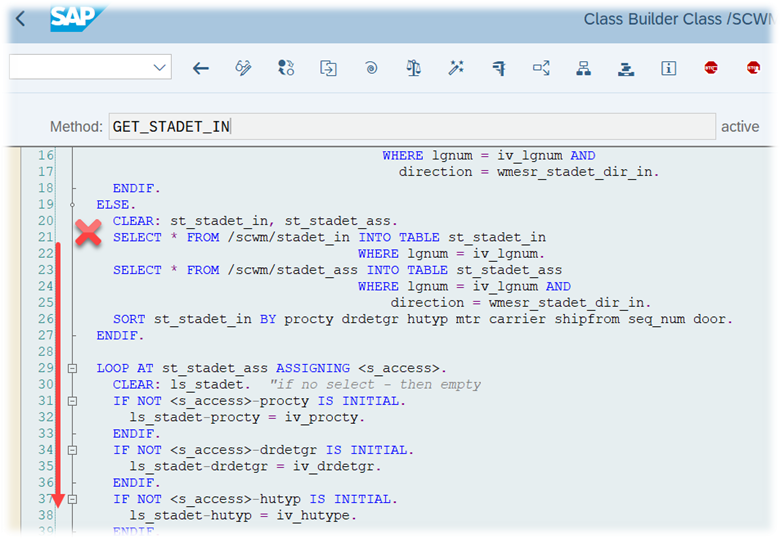
That was straightforward right!? This scenario however, is only executed if there are no manually assigned WOs. The latter is always checked one step earlier. Let’s assume a list of WOs has been manually assigned to the resource by the warehouse supervisor (e.g., via the warehouse monitor option, calling FM /SCWM/RSRC_WO_RSRC_ASSIGN_MON, which in turn calls FM /SCWM/RSRC_WHO_SELECT).
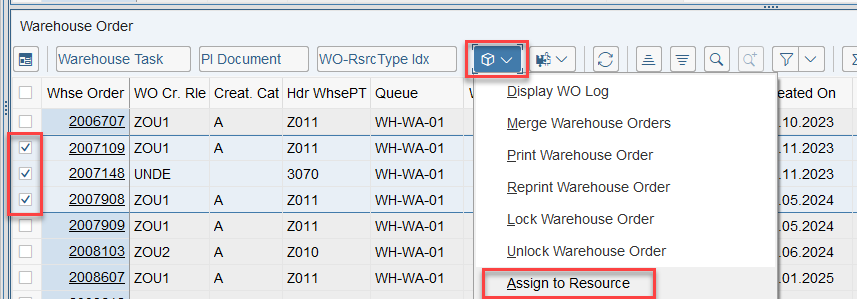
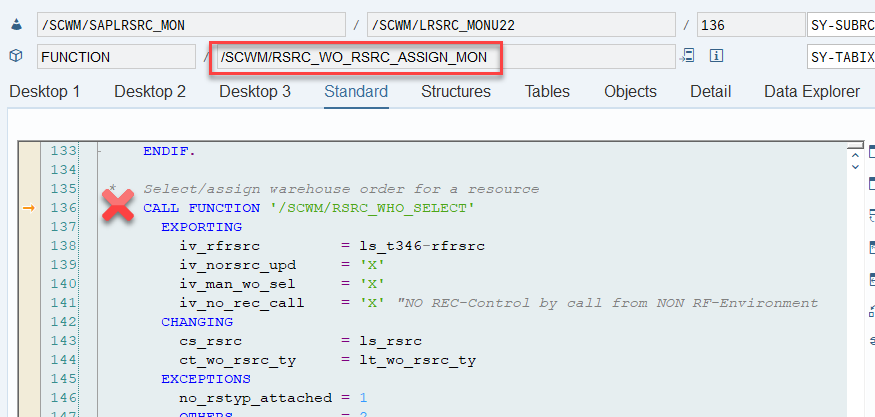
Assignments are read via FM /SCWM/RSRC_WHO_RSTYP_GET and, of course, always have a higher priority than non-assigned WOs. The sorting in this case – no surprise over here – is making use of the same ruleset that we saw before:
Options for enhancement
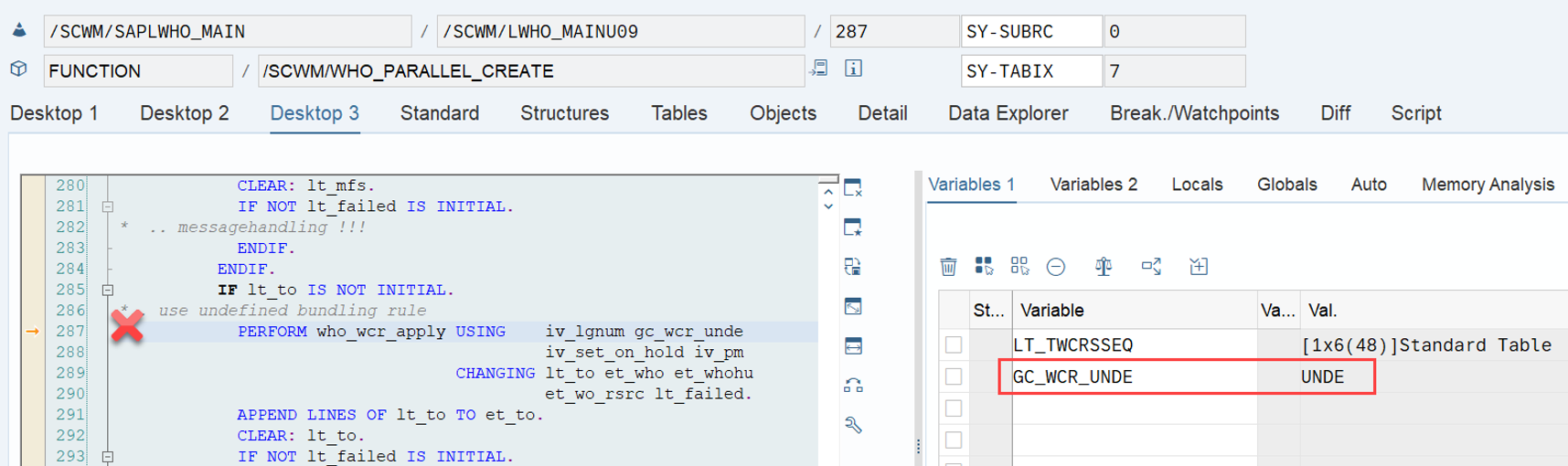
What is surprising though, is that EWM offers an option for a custom sorting in the pre-assignment context, which is not offered in the scenario where the WOs are not pre-assigned.
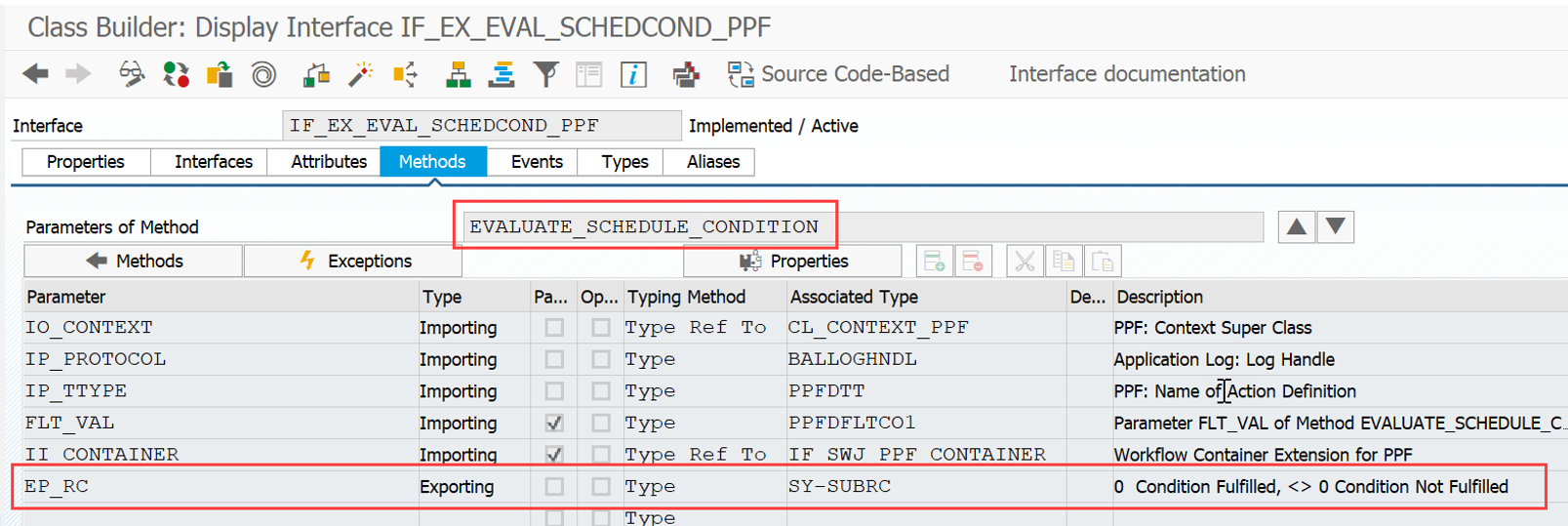
BAdi /SCWM/EX_RSRC_PROC_SEL
* With this BAdI you can influence the WO selection.
* You get the list of manual assigned WO’s and can
* resort them or
* delete WO from the list or
* return a new WO according your own selection (You must set LGNUM, WHO
* & CONTENT at least)
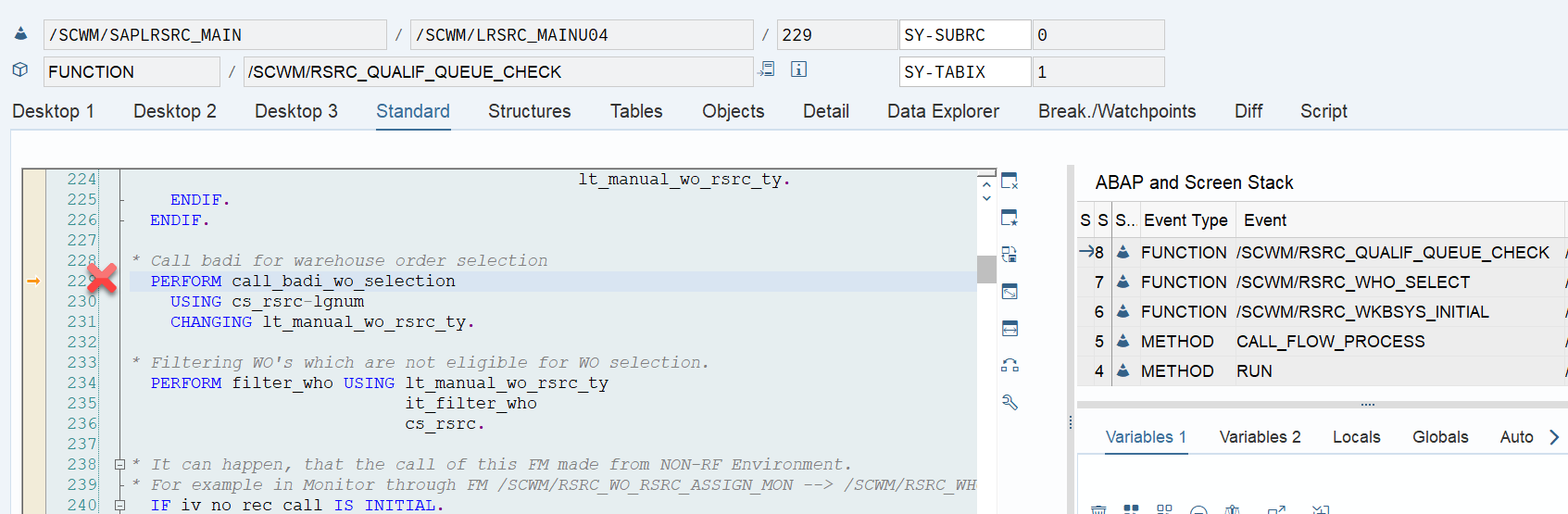
Question from a stupid EWM Consultant: Can somebody explain why this is BAdi not simply called in the same way in the non-pre-assignment context? If yes, please add your thoughts as a comment to the corresponding video!
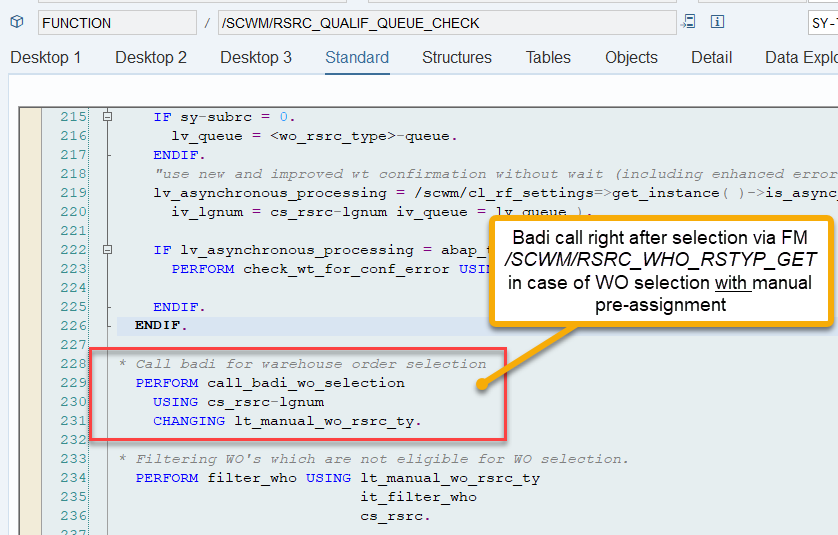
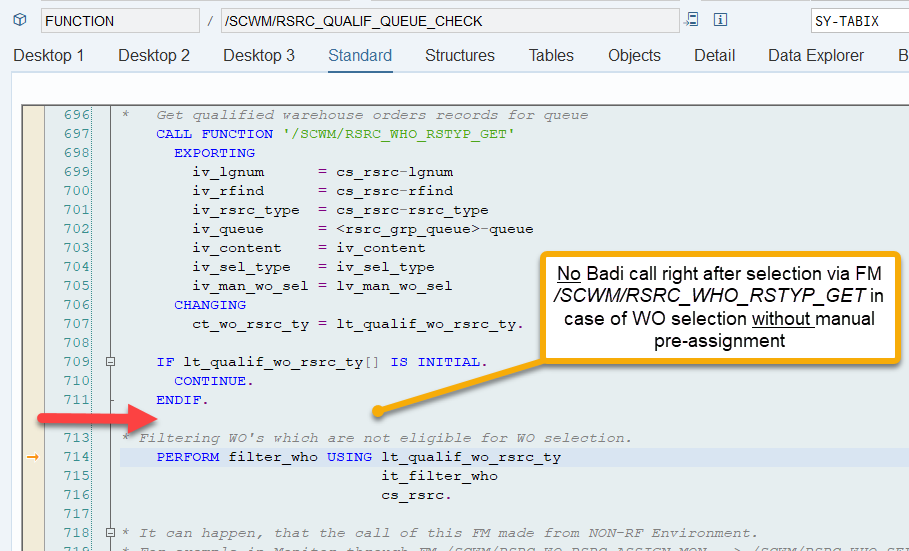
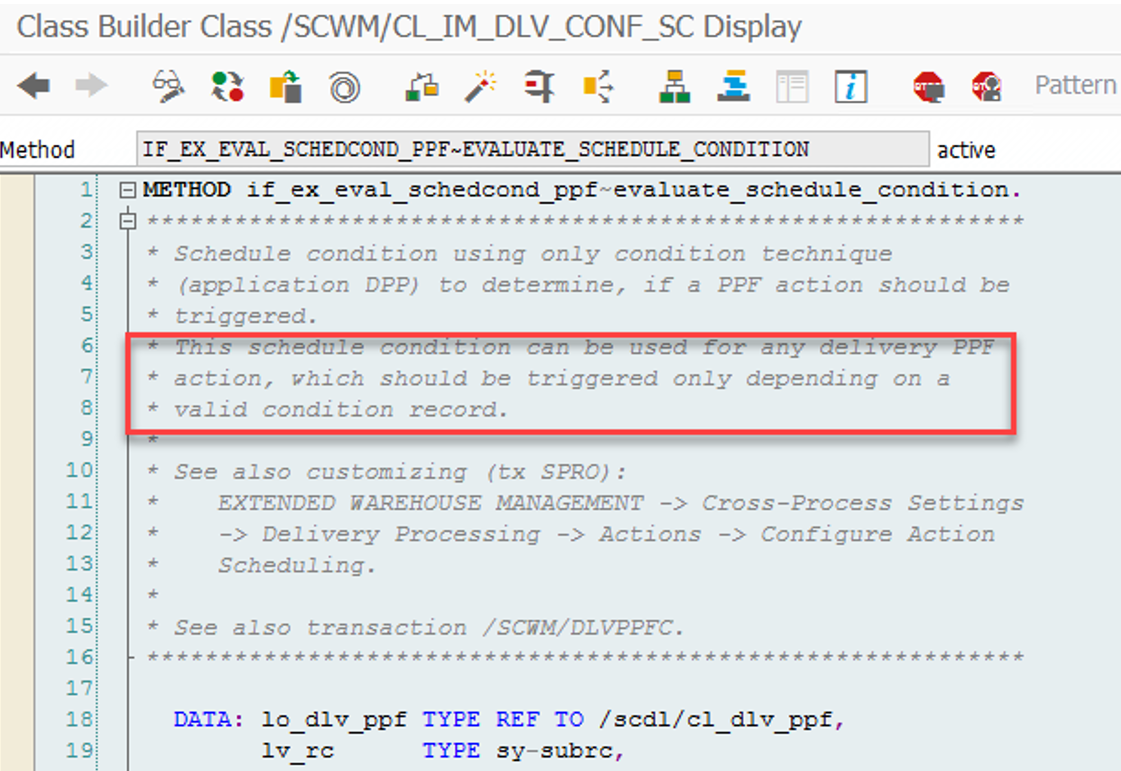
The filter_wo subroutine does not offer any option to manipulate the sorting here. Therefore, the only option to enhance the sorting is to intervene before the actual WO processing. You can include your own logic at the point when EWM creates the WOs and calculates the two values that are later used for sorting.
- LSD: I explained the option to enhance the LSD in this video (video & blog-post).
- Prioritization: The prioritization as the second sorting criterion can be manipulated via a custom logic using BAdi /SCWM/EX_RSRC_PROC_WO.
Fun facts / Party-knowledge
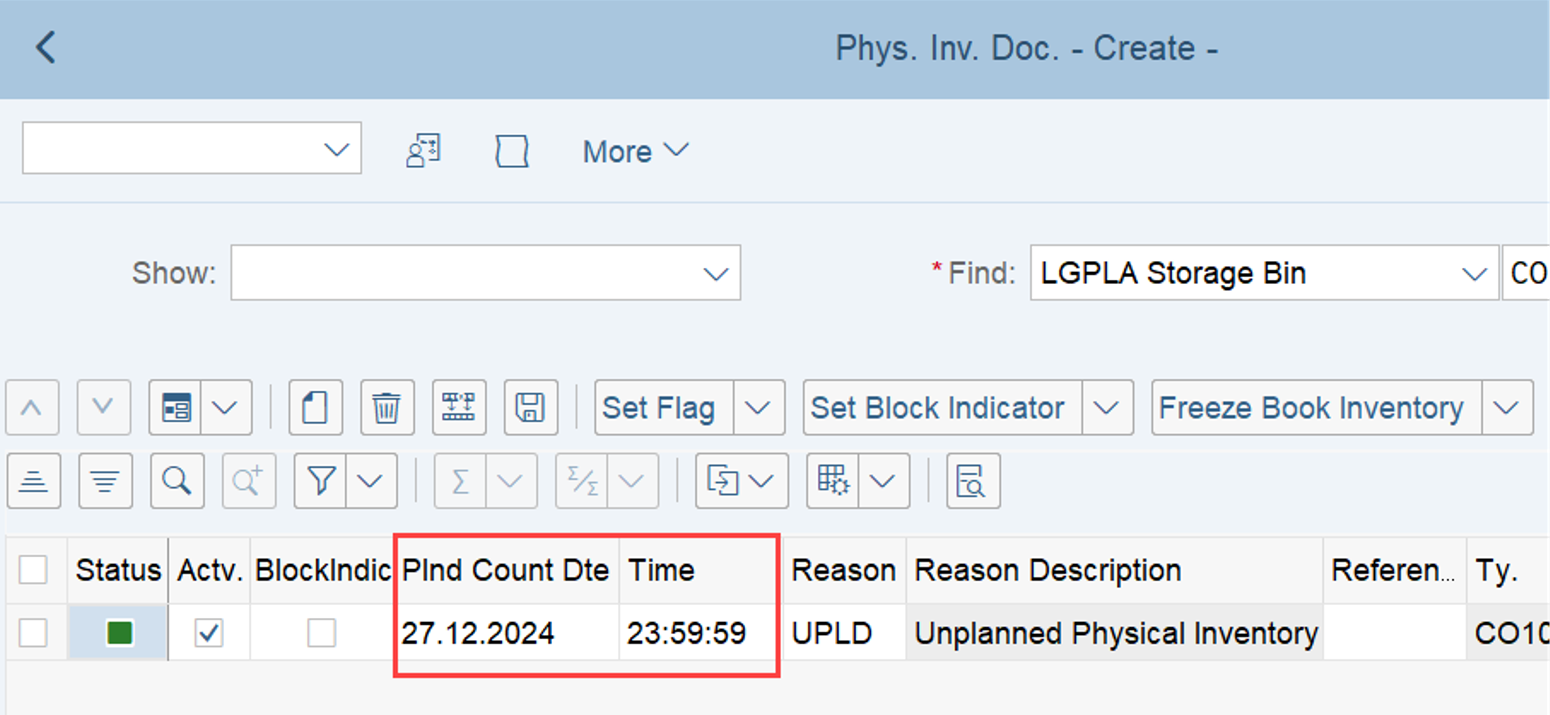
Sorting of WOs for physical inventory
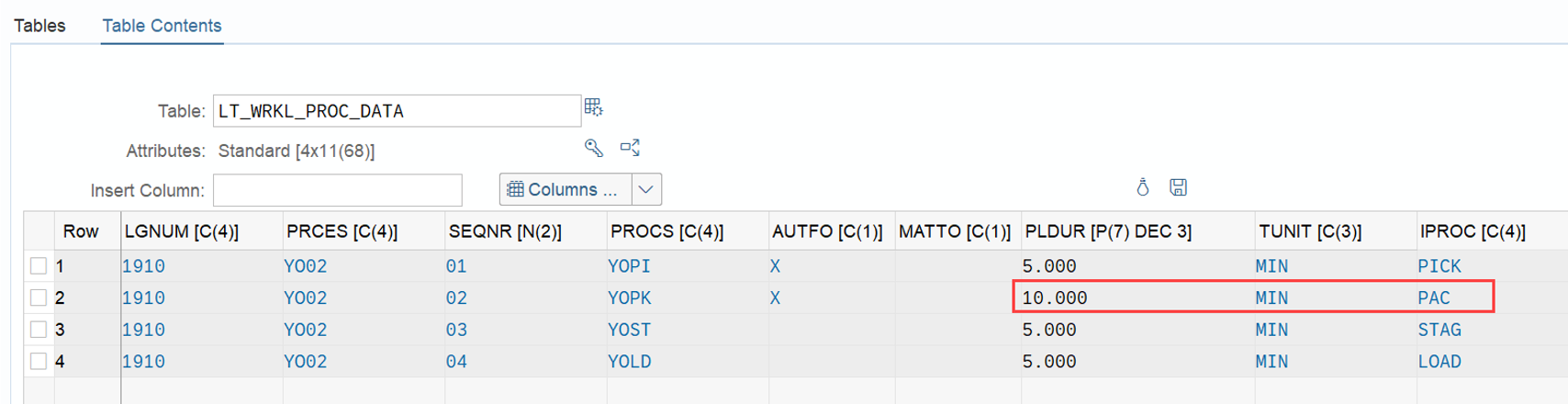
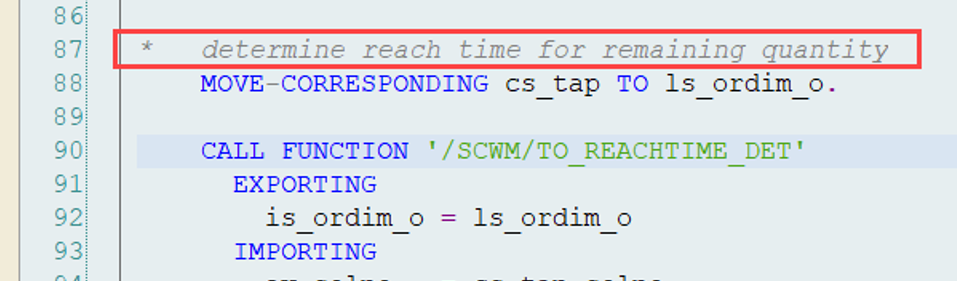
Nothing to reveal here. The sorting for PI WOs is based on the same criteria as for the normal WOs discussed above. As you learned in my campaign (video & blog-post) about the LSD calculation, for PI documents the LSD is derived from the planned count date. The priority is coming from the PI customizing.
Sorting in case of Task Interleaving
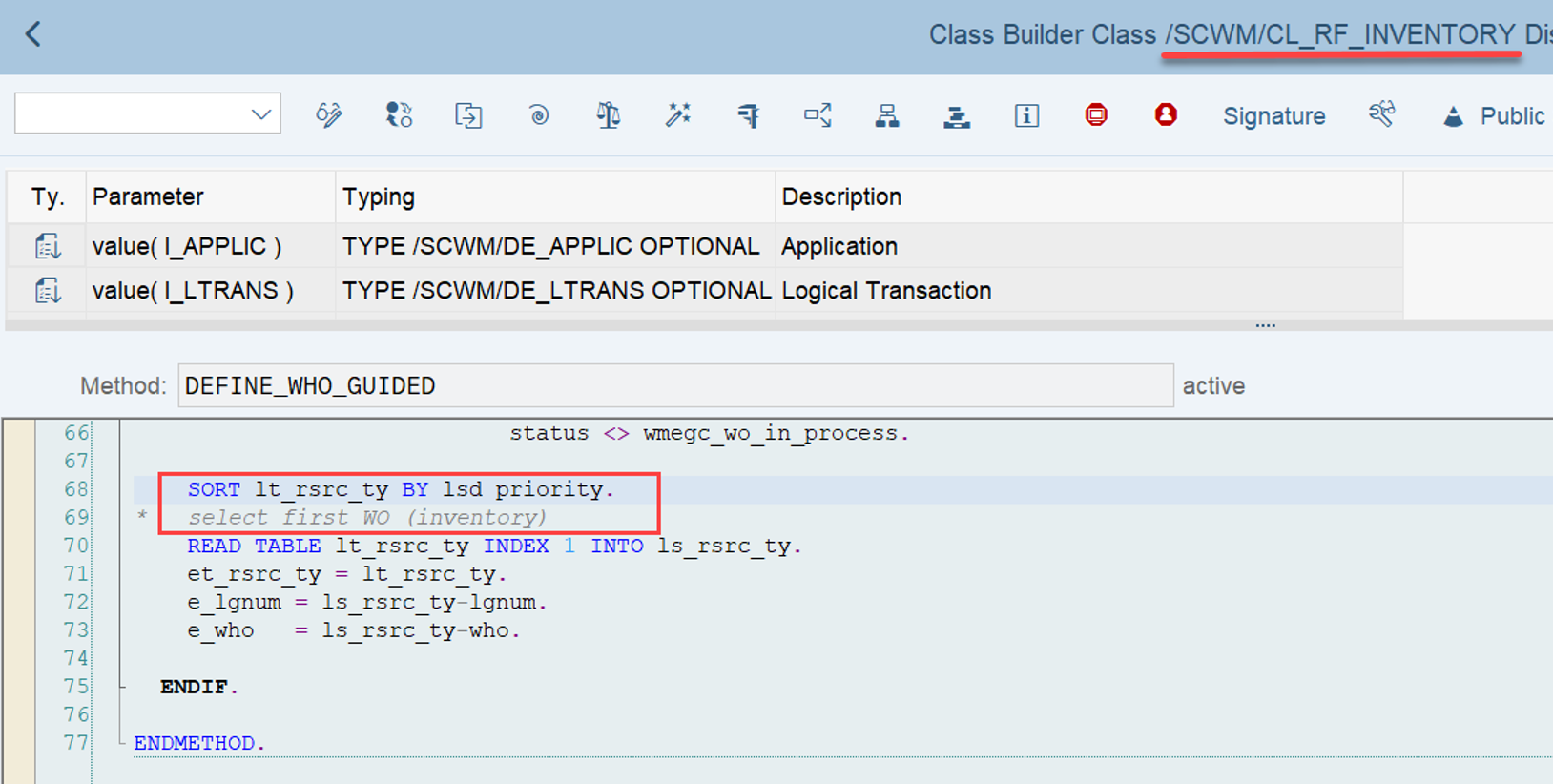
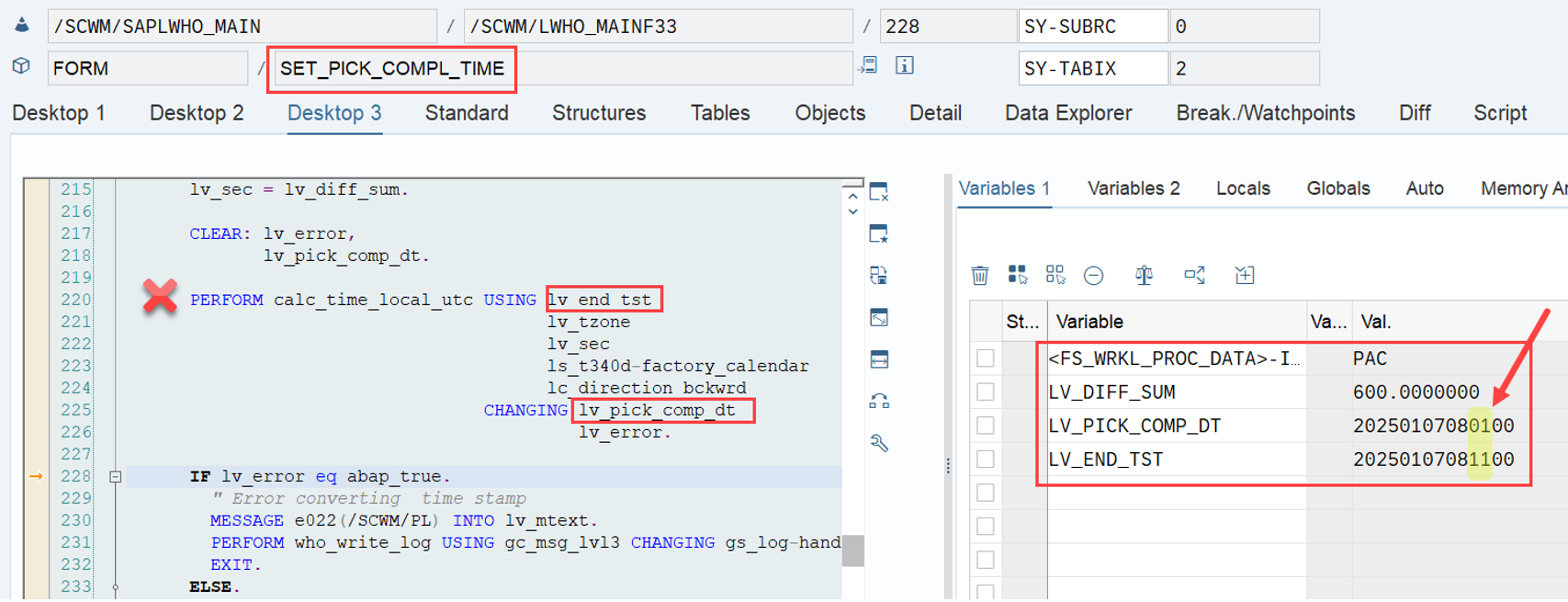
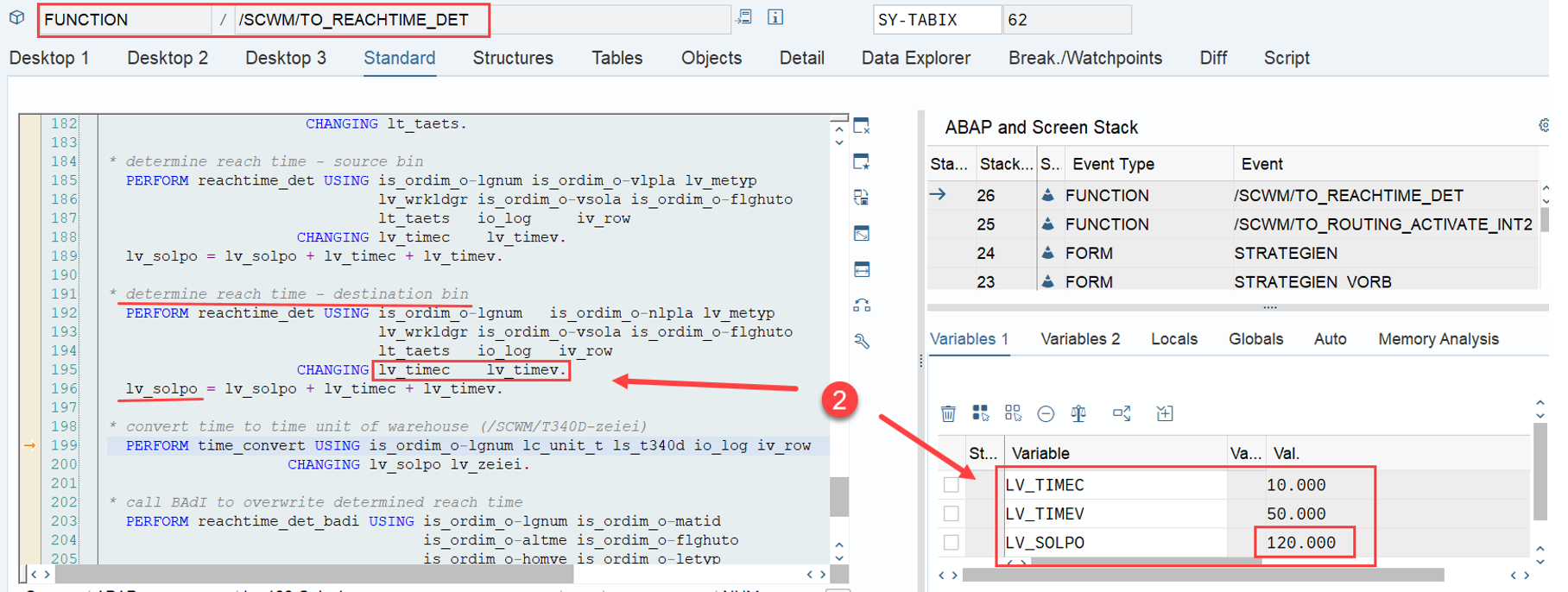
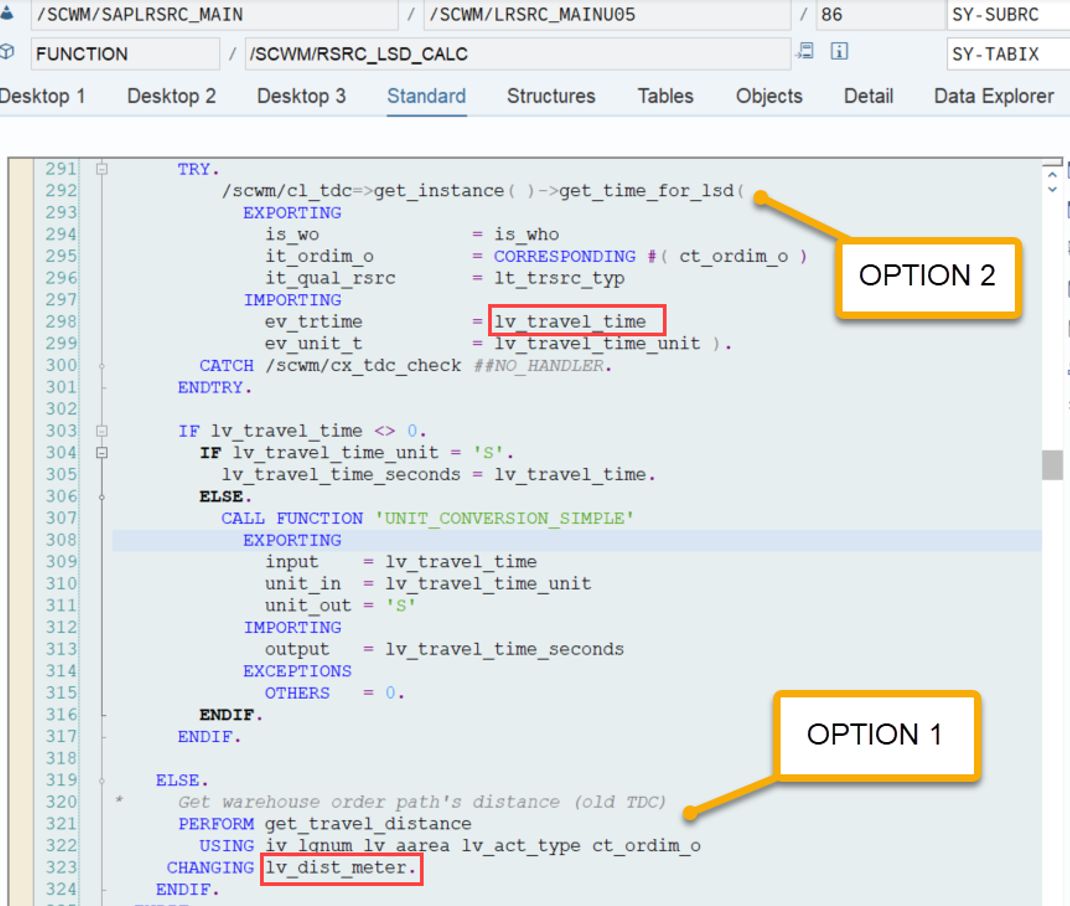
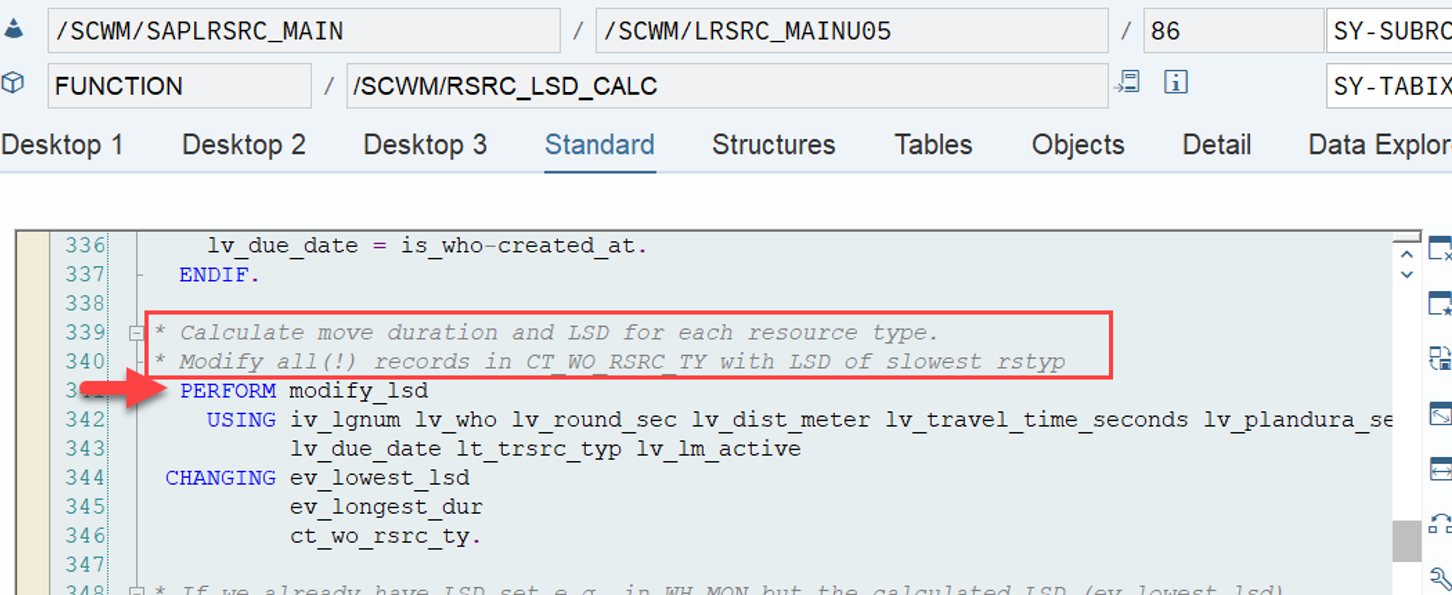
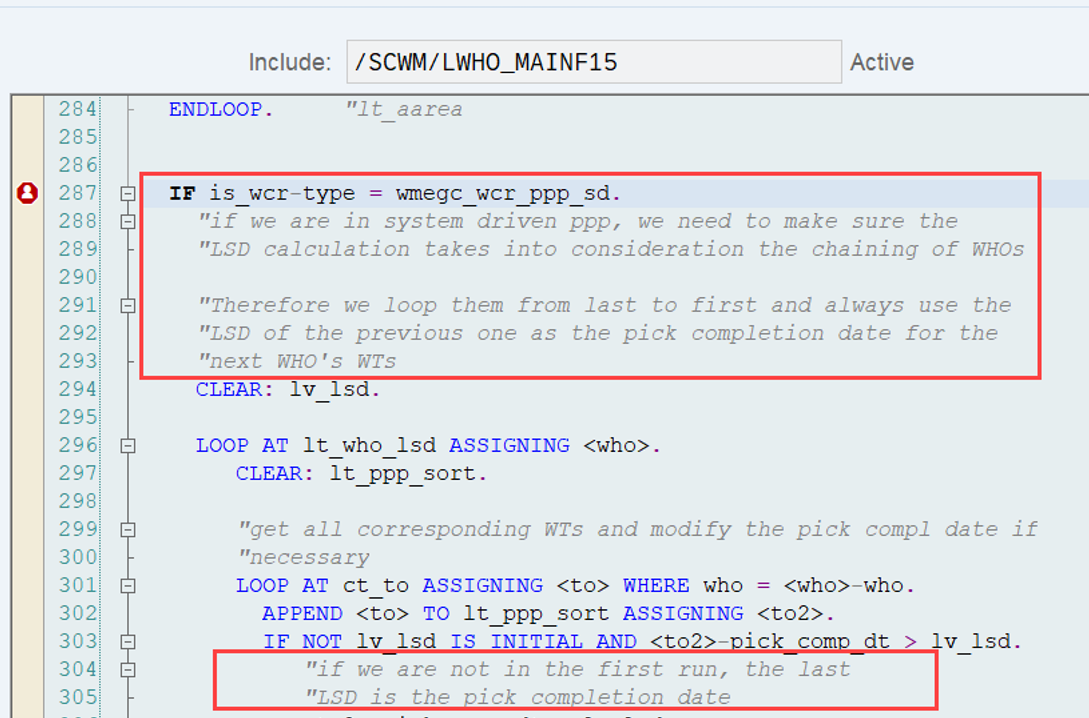
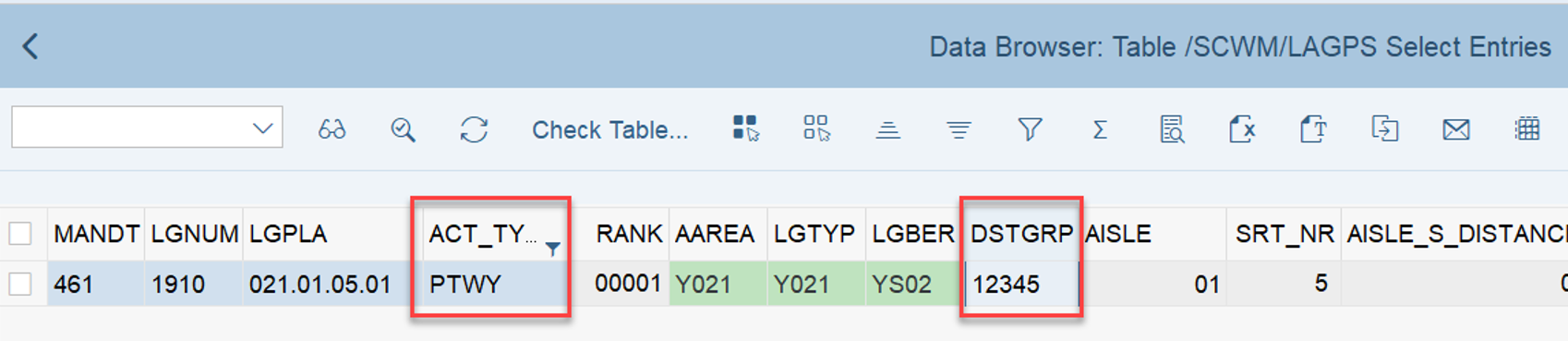
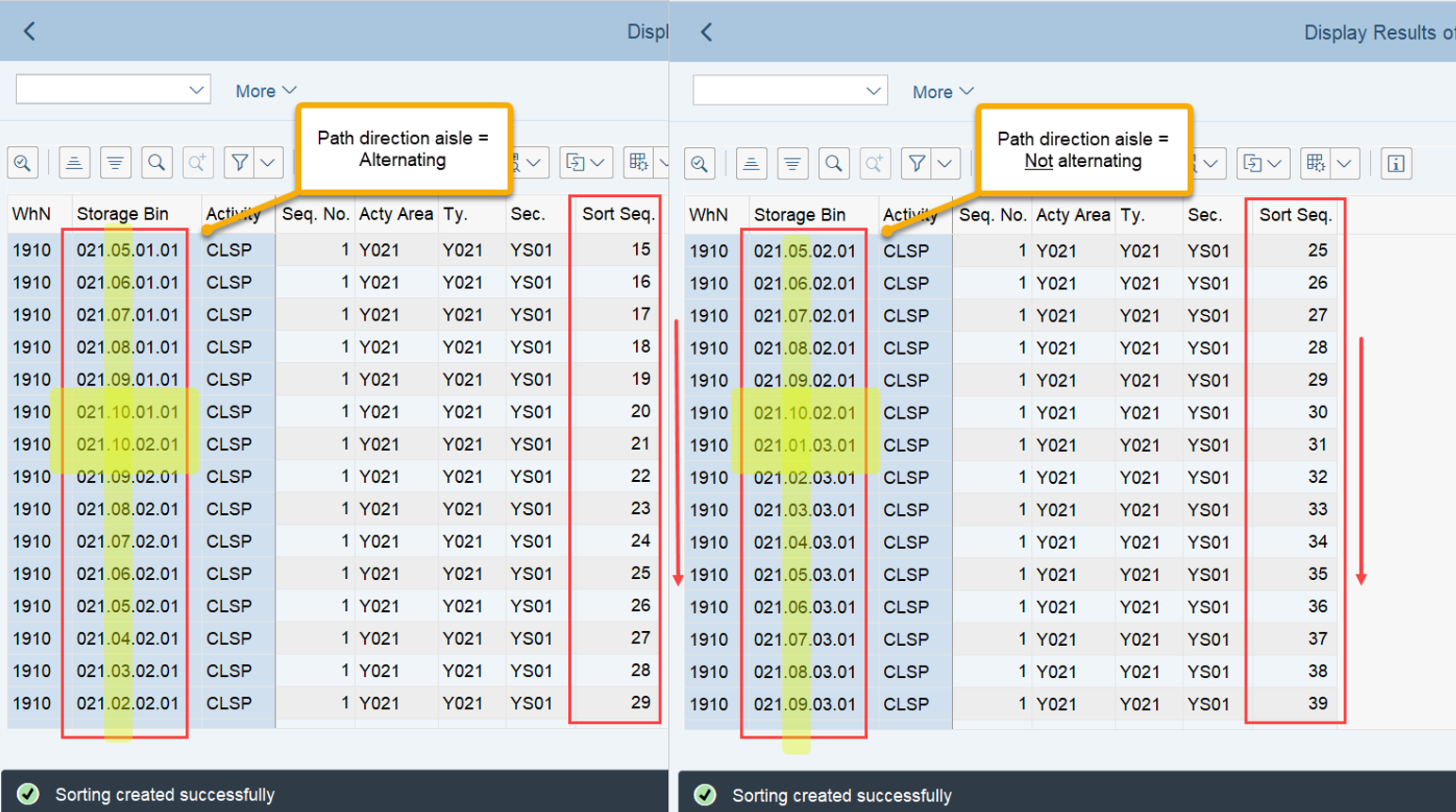
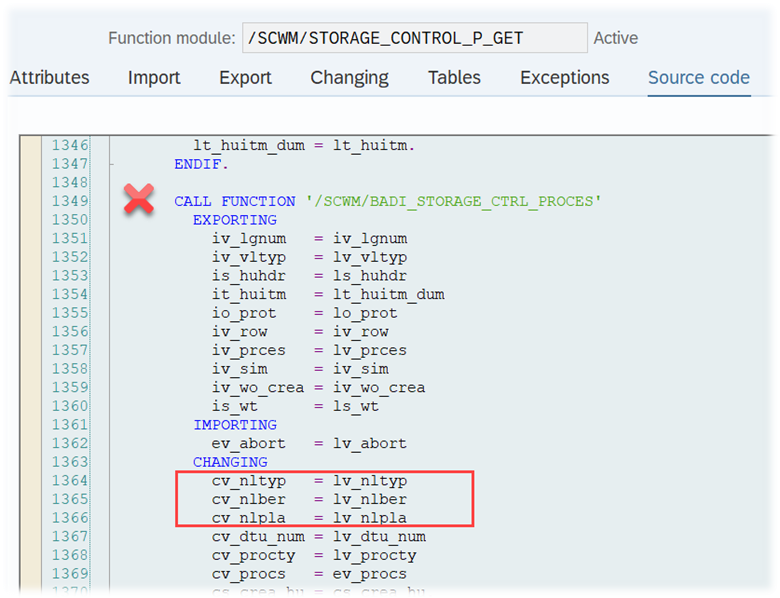
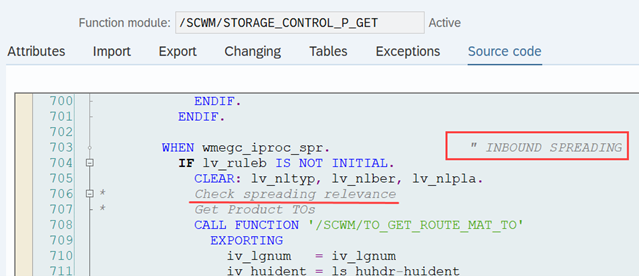
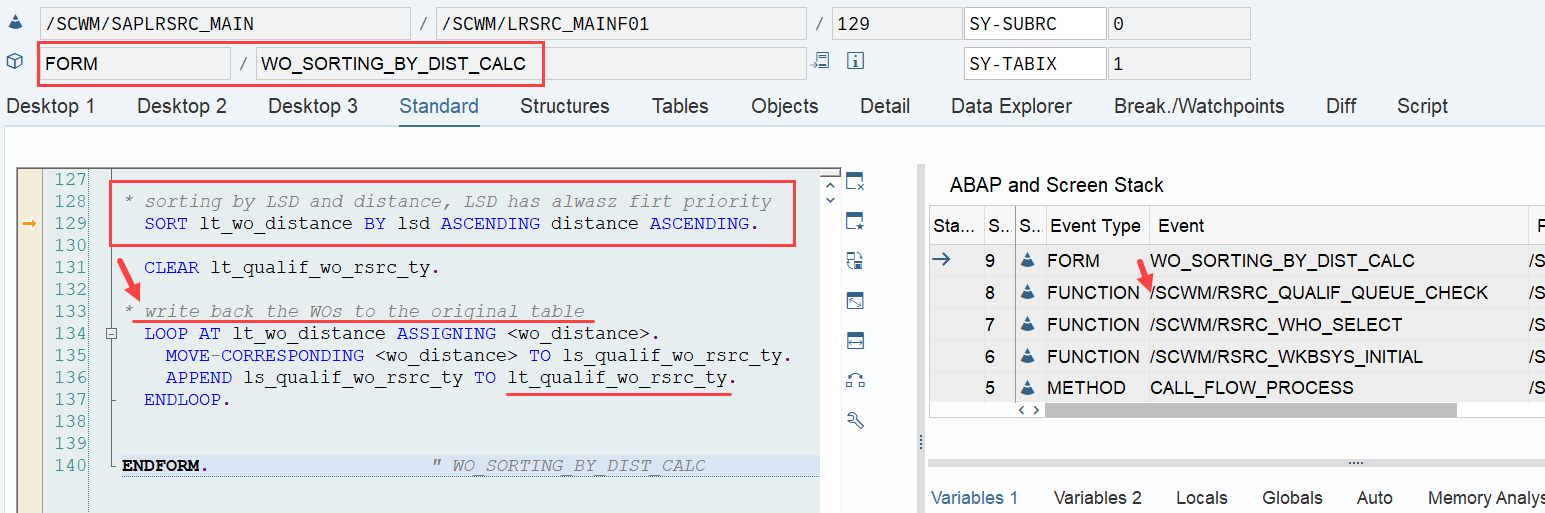
This is the most interesting part of this article in my opinion. If interleaving is active (refer to this video & blog-post if you are not familiar with the interleaving concept as such), EWM applies a slightly different logic for WO sorting, which I found only in the code (spent not that much time to browse all books to be honest). This occurs at the end of the function module FM /SCWM/RSRC_QUALIF_QUEUE_CHECK. Here, EWM considers the distance between the WOs instead of the priority used previously.
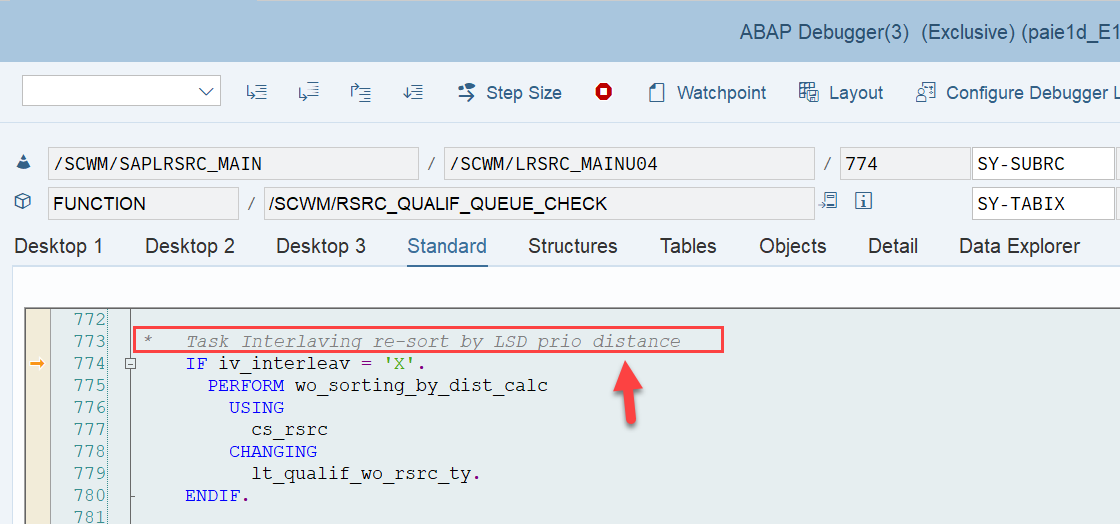
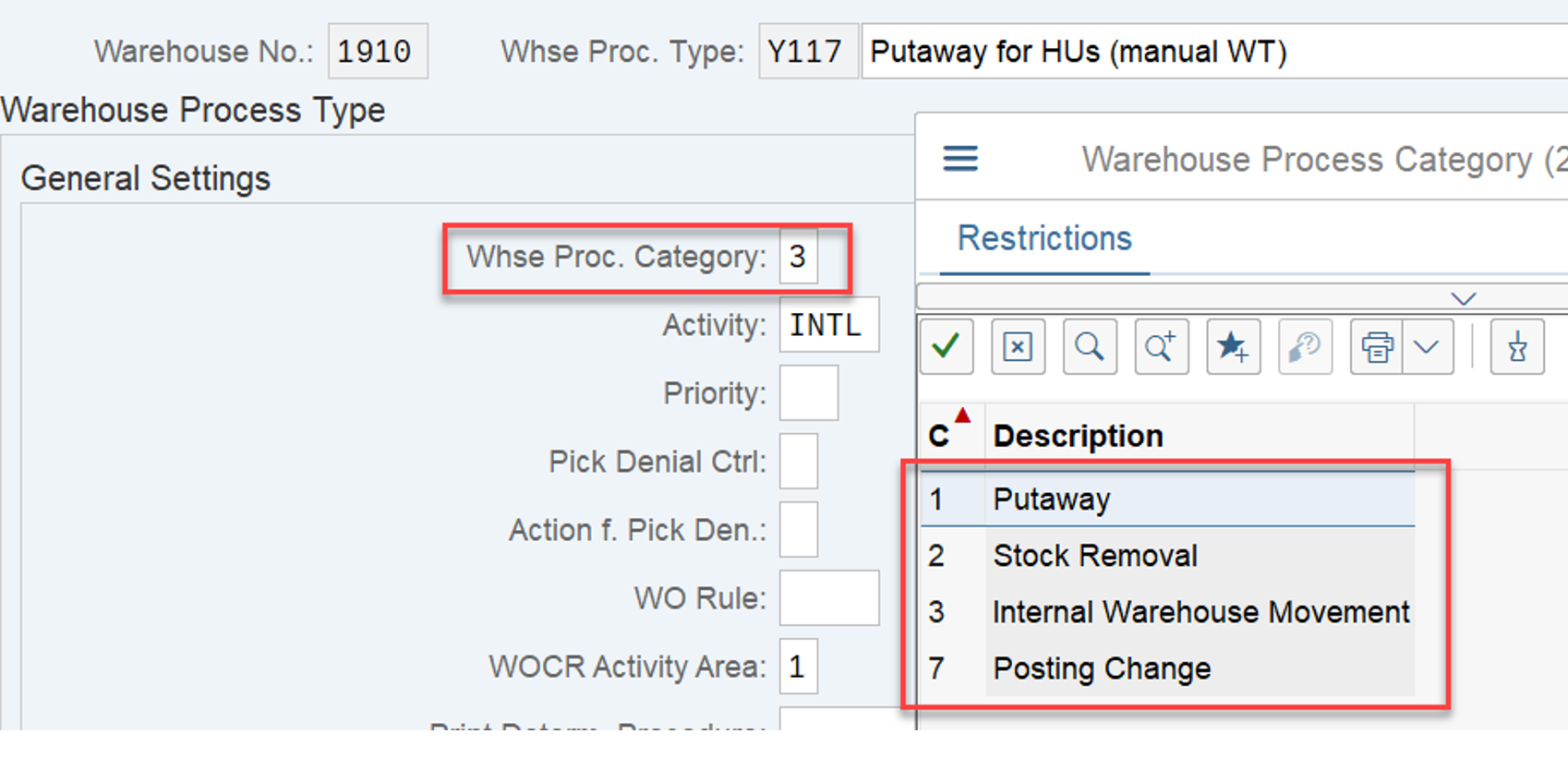
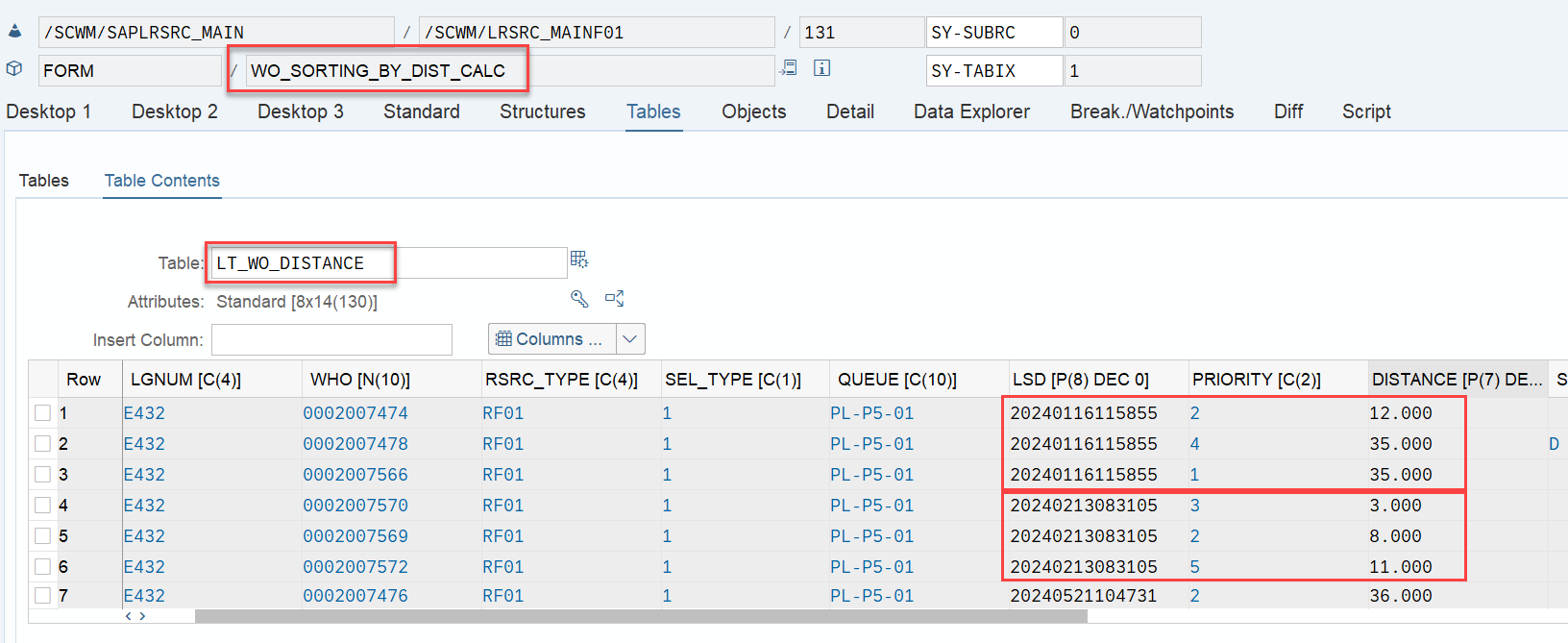
EWM loops over all WOs in the interleaving queue (~ the next queue from which it is supposed to pick a WO, based on the interleaving settings) and calculates the distances between the current position of the resource and the distance to the source bin of the first WT in every waiting WO in that queue:
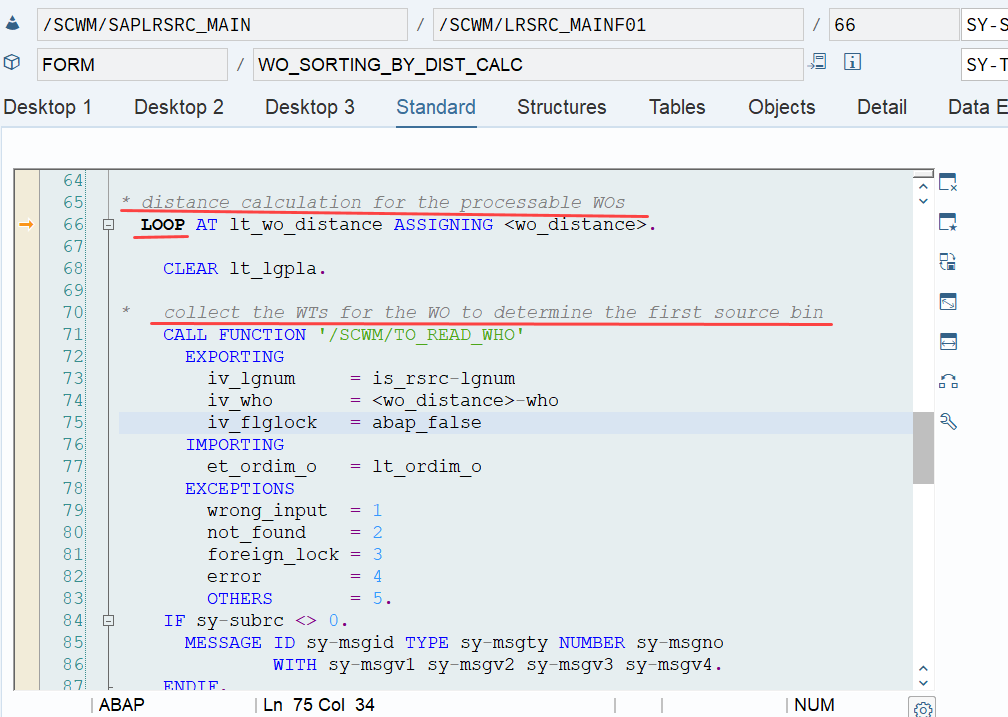
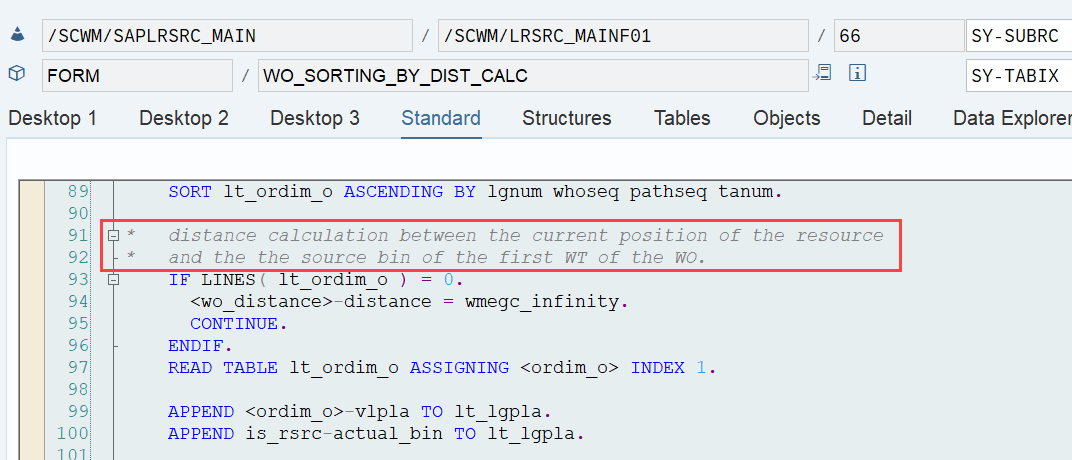
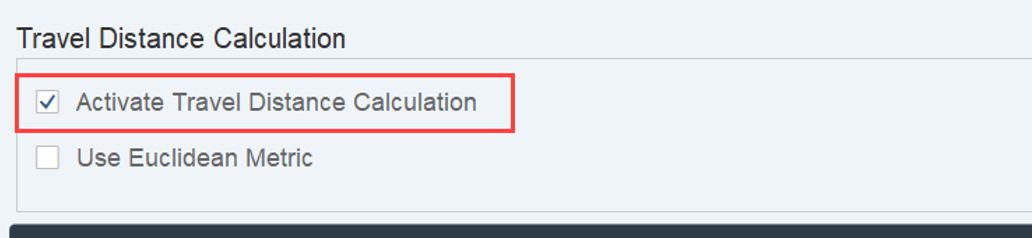
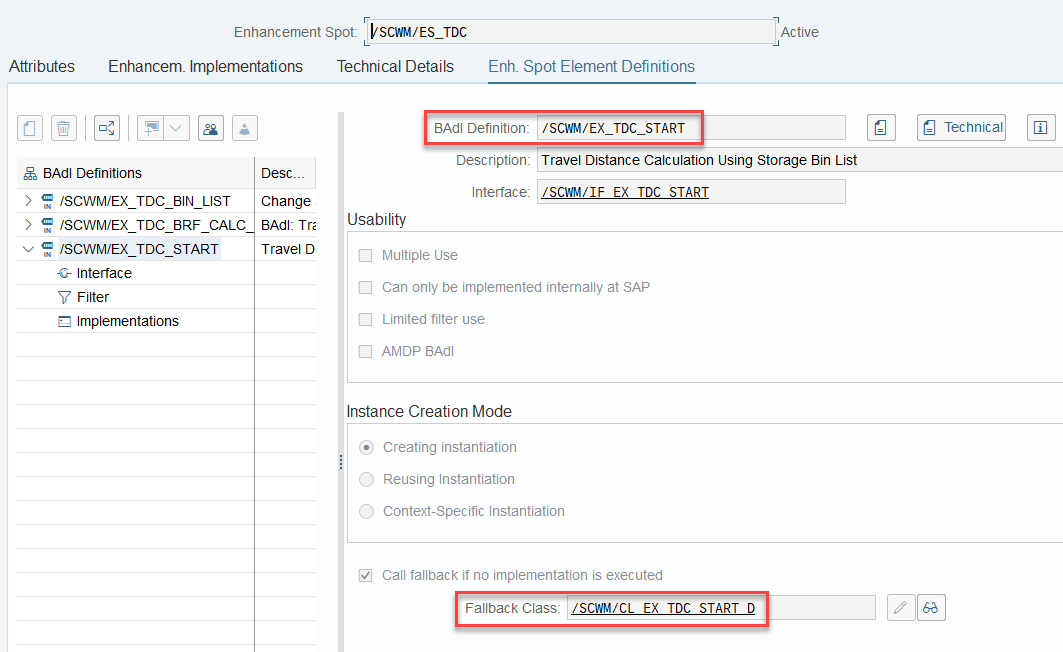
The distance calculation can be manipulated via BAdi /SCWM/EX_TDC_START. EWM itself calculates with the example/fallback class /SCWM/CL_EX_TDC_START_D of this BAdi (you should copy that class and use it as a base in case you want to include your custom logic here).
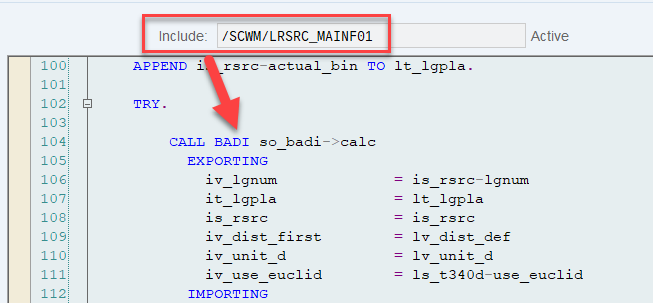
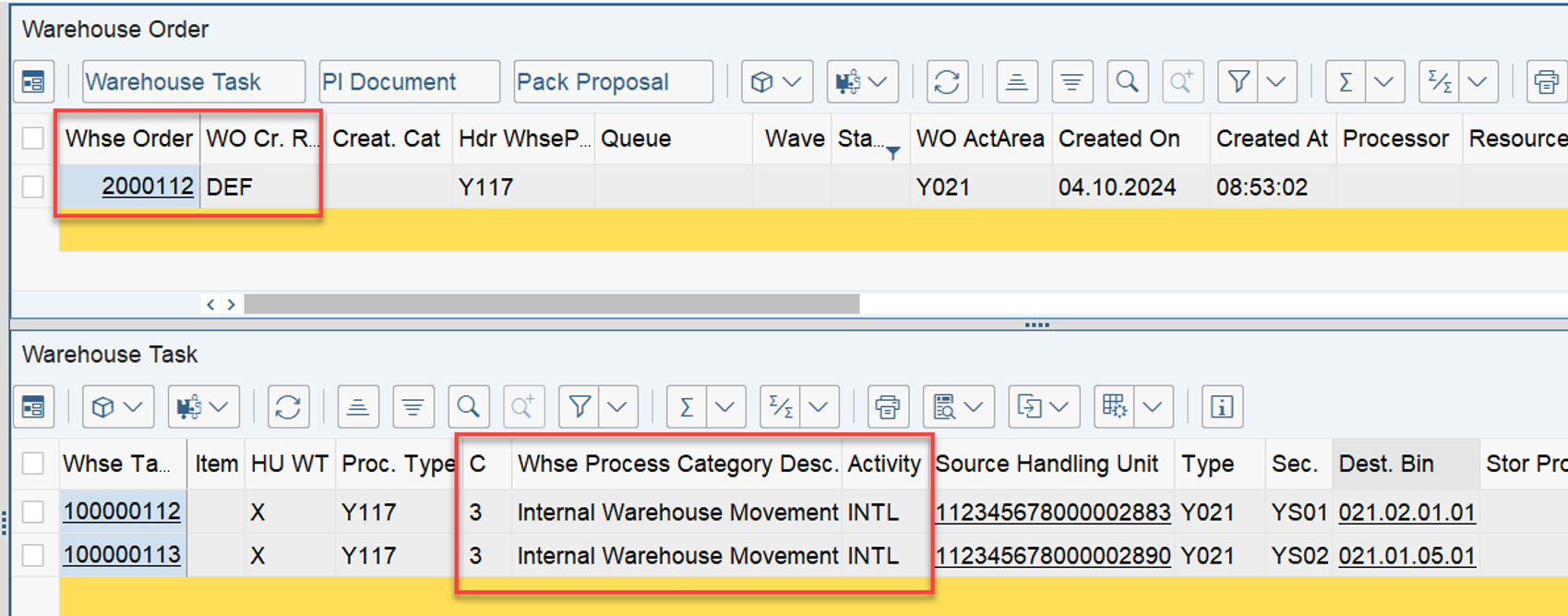
At the end can see that the LSD still has the highest value, but now the distance has a higher value than the ‘priority’ (which is no longer used in the context of interleaving).
A closing remark that I couldn’t overlook: I have great respect for the developers and I am forever grateful to have the opportunity to work with this software, but why the hell does a 300 billion company like SAP still ships software with so many typos in the comments of their code? Can’t the pretty printer check that as well? …or any kind of AI browsing through the code before it is being shipped?
Sorry… Back to our topic –
The following example visualizes the approach for sorting during interleaving, that I explained above:
…and that completes the last subtopic that I wanted to address here. As usual, I will not let you go without a quick summary of the most important points.
Summary
- Sorting is the same with or without manual pre-assignment of warehouse orders to resources (1.LSD > 2.Priority > 3.WO number)
- Only with manual pre-assignment the sorting can be changed in a clean and simple way (EWM offers a BAdi). Without manual pre-assignment, LSD and priority have to be manipulated during WO creation in order to implicitly change the sorting later
- PI WOs are being sorted based on the same criteria as other WOs
- In the context of task interleaving, the priority as a sorting criteria is replaced by the distance between the processing resource and the source bin of the first WT in the next WO
As we wrap up this blog post, I hope you found the information presented in a clear and digestible manner. While there may not have been many surprises, I trust that these last few minutes of reading have added to your EWM knowledge stack. Thank you for taking the time to read through!
Get my monthly blog-updates!
Subscribe to my Youtube channel!
The post Reveal SAP EWM – Warehouse Order sorting in Queues appeared first on WMexperts.online.